خانه تکنولوژی
معرفی تکنولوژی روز دنیاخانه تکنولوژی
معرفی تکنولوژی روز دنیامقدمه ای بر بینایی کامپیوتر
مقدمه ای بر بینایی کامپیوتر
 عکس سگ من ، پدینگتون ، با محدودیت جعبه هایی که برگها را نشان می دهند قطعاً خوراکی نیستند. (تصویر Roboflow.)
عکس سگ من ، پدینگتون ، با محدودیت جعبه هایی که برگها را نشان می دهند قطعاً خوراکی نیستند. (تصویر Roboflow.) بینایی رایانه می تواند انقلابی در جهان ایجاد کند. تا کنون ، بینایی رایانه ای به انسان کمک کرده است تا مشکلات زیادی را حل کند ، مانند کاهش ترافیک و نظارت بر سلامت محیط.
 تصاویر یک راکون جذاب ، لنی ، با حاشیه نویسی جعبه. (تصویر Roboflow.)
تصاویر یک راکون جذاب ، لنی ، با حاشیه نویسی جعبه. (تصویر Roboflow.) از لحاظ تاریخی ، برای انجام بینایی کامپیوتری ، به یک پیش زمینه فنی واقعا قوی نیاز داشتید. پس از خواندن این پست ، باید درک خوبی از بینایی کامپیوتر بدون پیش زمینه فنی قوی داشته باشید و باید مراحل لازم برای حل مشکل بینایی رایانه را بدانید.
بینایی کامپیوتر چیست؟
< p> در یک مفهوم اساسی ، بینایی رایانه ای این توانایی را دارد که یک کامپیوتر بتواند آنچه را که شبیه انسان است ببیند و درک کند.وقتی می خواهید از یک لیوان آب یک نوشیدنی بخورید ، چندین موارد مرتبط با بینایی اتفاق می افتد:
بینایی کامپیوتر یک چیز مشابه است ... اما برای رایانه ها!
مشکلات بینایی کامپیوتر در چند سطل مختلف قرار می گیرد. این مهم است زیرا مشکلات مختلف با روش های مختلف حل می شوند.
انواع مختلف مشکلات بینایی رایانه چیست؟
 انواع مشکلات بینایی رایانه. اقتباس از دوره استنفورد CS 231N. (تصویر Roboflow.)
انواع مشکلات بینایی رایانه. اقتباس از دوره استنفورد CS 231N. (تصویر Roboflow.) شش نوع مشکل بینایی رایانه وجود دارد که چهار مورد از آنها در تصویر بالا نشان داده شده است.
 Roboflow این تصویر را به عنوان اتوبوس مدرسه و نه تاکسی ، واگن برقی یا چیز دیگری به درستی تشخیص می دهد. (تصویر Roboflow.)
Roboflow این تصویر را به عنوان اتوبوس مدرسه و نه تاکسی ، واگن برقی یا چیز دیگری به درستی تشخیص می دهد. (تصویر Roboflow.)  GIF دود آتش سوزی در حال تشخیص است. (منبع تصویر.)
GIF دود آتش سوزی در حال تشخیص است. (منبع تصویر.)  تشخیص نوتروفیل ها ، نوعی گلبول سفید خون که نقش کلیدی در سیستم ایمنی بدن حیوانات دارد. (اعتبار: Matro Sokac ؛ مجاز به استفاده.)
تشخیص نوتروفیل ها ، نوعی گلبول سفید خون که نقش کلیدی در سیستم ایمنی بدن حیوانات دارد. (اعتبار: Matro Sokac ؛ مجاز به استفاده.)  اعمال تقسیم بندی معنایی بر روی تصویر سه نفر در دوچرخه. (منبع اصلی.)
اعمال تقسیم بندی معنایی بر روی تصویر سه نفر در دوچرخه. (منبع اصلی.)  اعمال تشخیص کلید واژه برای پنج نفر. (منبع تصویر.)
اعمال تشخیص کلید واژه برای پنج نفر. (منبع تصویر.) چگونه می توانم مشکلات بینایی کامپیوتر را حل کنم؟
اگر می خواهید رایانه شما به شما در حل مشکلات مربوط به داده ها کمک کند ، معمولاً یک سری مراحل را دنبال می کنید. همین امر در مورد مشکلات بینایی رایانه صادق است ، مگر اینکه مراحل کمی متفاوت به نظر برسند.
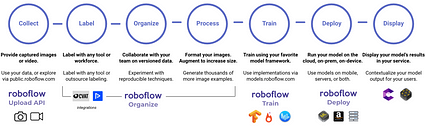 یک فرآیند هفت مرحله ای برای حل مشکلات بینایی رایانه. (تصویر Roboflow.)
یک فرآیند هفت مرحله ای برای حل مشکلات بینایی رایانه. (تصویر Roboflow.) ما هر یک از این مراحل را طی می کنیم ، با این هدف که در پایان فرآیند مراحل مورد نیاز برای حل مشکل بینایی کامپیوتر و همچنین یک مشکل خوب را بدانید. نمای کلی رایانه.
 سه تصویر از آبراهام لینکلن. (منبع اصلی.)
سه تصویر از آبراهام لینکلن. (منبع اصلی.) اگر هدف شما این است که رایانه خود را بشناسید تا بفهمد سگ ها چگونه به نظر می رسند ، پس کامپیوتر به شما نیاز دارد که به او بگویید کدام پیکسل ها مربوط به یک سگ است! اینجاست که تصویر خود را برچسب گذاری یا حاشیه نویسی می کنید. در زیر تصویری از مجموعه داده مادون قرمز حرارتی است که به طور فعال در حال حاشیه نویسی است. یک جعبه محدود کننده در اطراف فرد کشیده شده و یک جعبه محدود کننده جداگانه در اطراف سگ کشیده شده است. این کار توسط یک انسان انجام می شود. (از آنجا که این تصویر دارای بیش از یک شیء است و از کادرهای محدود کننده استفاده می کند ، می دانیم که این تصویر برای یک کار تشخیص شی استفاده می شود!) این کادرهای محدود کننده از طریق ابزاری به نام Microsoft VoTT یا ابزار برچسب گذاری ویژوال شی اضافه می شوند. < /p> 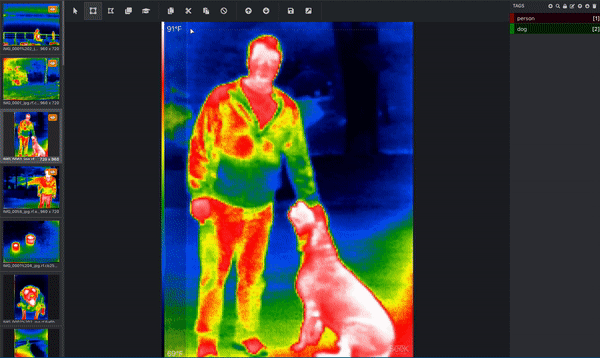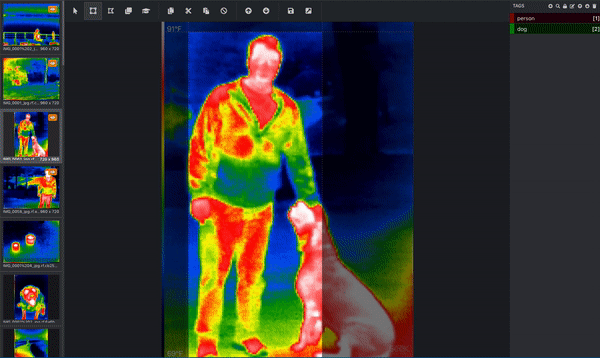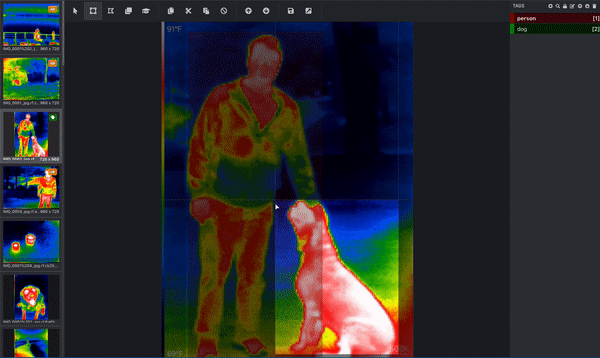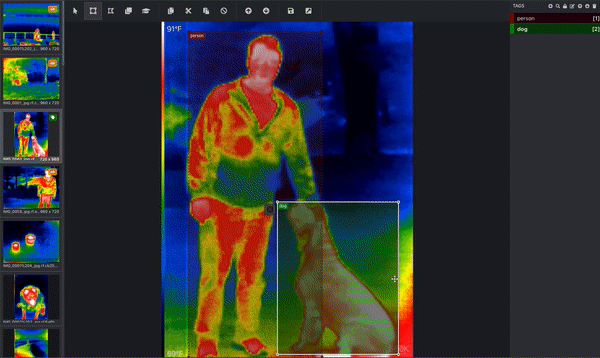 حاشیه نویسی تصویر با Microsoft VoTT ؛ ما یک آغازگر در مورد نحوه استفاده از VoTT نوشتیم. (تصویر Roboflow.)
حاشیه نویسی تصویر با Microsoft VoTT ؛ ما یک آغازگر در مورد نحوه استفاده از VoTT نوشتیم. (تصویر Roboflow.)
این تنها ابزار نیست - شما می توانید از ابزارهای دیگر مانند CVAT (Computer Vision Annotation Tool) ، برنامه وب Roboflow یا خود API بارگذاری ما استفاده کنید.
هنگامی که داده ها را جمع آوری کردید و ابزار خود را برای برچسب گذاری انتخاب کردید ، شروع به برچسب زدن می کنید! شما باید سعی کنید تا آنجا که می توانید تصاویر را برچسب گذاری کنید. اگر تعداد تصاویر شما بیش از آن چیزی است که می توانید برچسب گذاری کنید ، در اینجا چند استراتژی یادگیری فعال برای برچسب زدن موثرتر تصاویر آمده است.
 برخی مراحل رایج پیش پردازش و افزایش تصویر در Roboflow موجود است. (تصویر Roboflow.)
برخی مراحل رایج پیش پردازش و افزایش تصویر در Roboflow موجود است. (تصویر Roboflow.) همچنین می توانید کاری به نام افزایش تصویر انجام دهید. این کمی متفاوت است - این فقط بر تصاویری که شما برای آموزش مدل خود استفاده می کنید (نحوه مشاهده کامپیوتر را آموزش دهید) تأثیر می گذارد. در یک جمله ، بزرگنمایی تصویر تغییرات کوچکی در تصاویر شما ایجاد می کند به طوری که حجم نمونه شما (تعداد تصاویر) افزایش می یابد و به احتمال زیاد تصاویر شما منعکس کننده شرایط دنیای واقعی هستند. به عنوان مثال ، می توانید جهت تصویر خود را به طور تصادفی تغییر دهید. بگویید با تلفن خود از یک کامیون عکس می گیرید. اگر رایانه آن تصویر دقیق را ببیند ، ممکن است کامیون را تشخیص دهد. اگر رایانه تصویری مشابه از یک کامیون را مشاهده کرد که با دست کسی چند درجه چرخانده شده است ، ممکن است رایانه تشخیص کامیون را دشوارتر کند. افزودن مراحل تقویت ، حجم نمونه شما را با ایجاد کپی از تصاویر اصلی و سپس کمی مزاحمت برای آنها افزایش می دهد تا مدل شما دیدگاه های دیگری را نیز ببیند.
 نمی توانم در مورد سگها صحبت کنم و تصویری از سگ من ، پدینگتون ندارم! (تصویر توسط نویسنده.)
نمی توانم در مورد سگها صحبت کنم و تصویری از سگ من ، پدینگتون ندارم! (تصویر توسط نویسنده.) روشهای مختلفی وجود دارد که ما می توانیم میزان رایانه ما را به خوبی تشخیص دهیم.
مدلهای مختلفی وجود دارد که می توانند برای مشکلات تصویر استفاده شود ، اما رایج ترین (و معمولاً بهترین عملکرد!) شبکه عصبی پیچشی است. اگر از یک شبکه عصبی متغیر استفاده می کنید ، بدانید که بسیاری از قضاوت ها در معماری مدل وارد شده اند که بر قدرت دیدن رایانه شما تأثیر می گذارد! خوشبختانه برای ما ، تعداد زیادی معماری مدل از پیش تعیین شده وجود دارد که برای مشکلات مختلف بینایی رایانه بسیار خوب عمل می کند.
 یک مدل تشخیص شیء YOLOv5 که پیش بینی های زمان واقعی را با دوچرخه ، ماشین و شخص ایجاد می کند. (تصویر Roboflow.)
یک مدل تشخیص شیء YOLOv5 که پیش بینی های زمان واقعی را با دوچرخه ، ماشین و شخص ایجاد می کند. (تصویر Roboflow.) ممکن است بخواهید مدل خود را در برنامه ای قرار دهید ، بنابراین رایانه شما می تواند پیش بینی ها را در زمان واقعی مستقیماً از تلفن شما ایجاد کند! ممکن است بخواهید به برنامه ای در رایانه خود ، یا به AWS ، یا چیزی داخلی در تیم خود بپردازید. ما قبلاً به طور مفصل در مورد یکی از روشهای استقرار مدل بینایی رایانه در اینجا نوشتیم. اگر حداقل کمی با Python و API ها آشنا هستید ، این مستندات در مورد استنباط در بینایی رایانه می تواند مفید باشد!
صرف نظر از مراحل بعدی شما ، کار انجام نمی شود اینجا کاملاً تمام نمی شود! کاملاً مستند است که مدلهایی که به خوبی روی تصاویری که به آن می دهید کار می کنند ، ممکن است با گذشت زمان بدتر کار کنند. (ما برخی از تحقیقات گوگل در مورد این مشکل عملکرد مدل را مطالعه کردیم و نکات مهم ما را شرح دادیم.) با این حال ، ما امیدواریم که شما به این نتیجه رسیده اید که به هدفی که در ابتدای این پست نوشتیم رسیده اید:
از اینکه تا اینجا با ما همراه بودید متشکریم! هرگونه سوال یا منابع اضافی که در نظرات دارید به ما اطلاع دهید - و اگر چیزی در ارتباط با بینایی رایانه ایجاد می کنید ، خوشحال می شویم ببینیم شما چه کار می کنید!
در ابتدا در https: //blog.roboflow منتشر شده است .com در 23 نوامبر 2020.
OpenAI دو مدل ترانسفورماتور را منتشر می کند که به طور جادویی زبان و بینایی رایانه را پیوند می دهند
OpenAI دو مدل ترانسفورماتور را منتشر می کند که به طور جادویی زبان و بینایی رایانه را پیوند می دهند
CLIP و DALL · E از GPT-3 برای تسلط بر کارهای پیچیده بینایی رایانه الهام می گیرد.
 منبع: https://www.rev.com/blog/what-is-gpt-3-the-new- openai-language-model
منبع: https://www.rev.com/blog/what-is-gpt-3-the-new- openai-language-model معرفی گرافیک TensorFlow: گرافیک کامپیوتری با یادگیری عمیق همراه است
معرفی گرافیک TensorFlow: گرافیک کامپیوتری با یادگیری عمیق همراه است
ارسال شده توسط ژولین والنتین و سوفین بوعزیز

مخزن Github: https://github.com/tensorflow/graphics
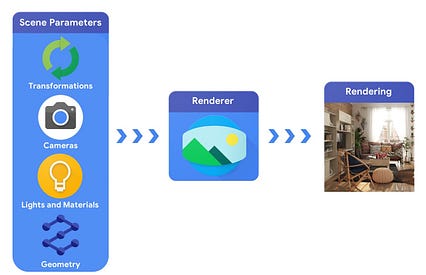
در چند سال گذشته شاهد افزایش گرافیک های متمایز جدید بوده ایم لایه هایی که می توانند در معماری شبکه عصبی وارد شوند. از ترانسفورماتورهای فضایی گرفته تا پردازنده های گرافیکی متمایز ، این لایه های جدید از دانش به دست آمده در طول سال های بینایی رایانه و تحقیقات گرافیکی برای ایجاد معماری های جدید و کارآمدتر شبکه استفاده می کنند. مدل سازی صریح مقدمات و محدودیت های هندسی در شبکه های عصبی ، راه را برای معماری هایی باز می کند که می توان به طور قوی ، کارآمد و مهمتر از همه ، به شیوه ای تحت نظارت خود آموزش دید. به اشیاء سه بعدی و موقعیت مطلق آنها در صحنه ، توصیف موادی که از آنها ساخته شده است ، چراغ ها و دوربین نیاز دارد. این توصیف صحنه سپس توسط یک ارائه کننده تفسیر می شود تا تصویری مصنوعی ایجاد شود.
 < /img>
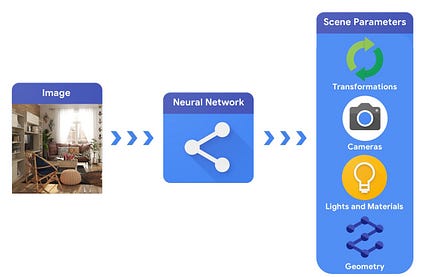
< /img> در مقایسه ، یک سیستم بینایی کامپیوتری از یک تصویر شروع می کند و سعی می کند پارامترهای صحنه را استنباط کند. این امکان پیش بینی اجسام موجود در صحنه ، موادی که از آنها ساخته شده است و موقعیت و جهت سه بعدی آنها را می دهد.
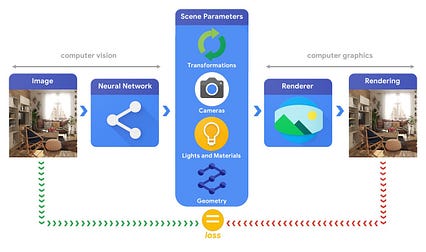
آموزش سیستم های یادگیری ماشین قادر به حل این وظایف پیچیده بینایی سه بعدی اغلب به حجم زیادی داده نیاز دارد. از آنجا که برچسب زدن داده ها یک فرایند پرهزینه و پیچیده است ، مهم است که سازوکارهایی برای طراحی مدل های یادگیری ماشین وجود داشته باشد که بتوانند جهان سه بعدی را در حالی که بدون نظارت زیاد آموزش دیده اند درک کنند. ترکیب بینایی رایانه ای و تکنیک های گرافیکی رایانه ای ، فرصتی منحصر به فرد برای استفاده از حجم وسیعی از داده های بدون برچسب به آسانی در اختیار شما قرار می دهد. همانطور که در تصویر زیر نشان داده شده است ، به عنوان مثال ، می توان با استفاده از تجزیه و تحلیل سنتز در جایی که سیستم بینایی پارامترهای صحنه را استخراج می کند و سیستم گرافیکی بر اساس آنها تصویر را باز می گرداند ، به این مهم دست یافت. اگر رندر با تصویر اصلی مطابقت داشته باشد ، سیستم بینایی پارامترهای صحنه را به طور دقیق استخراج کرده است. در این راه اندازی ، بینایی رایانه ای و گرافیک رایانه ای دست به دست هم داده و یک سیستم یادگیری ماشینی واحد شبیه به رمزگذار خودکار تشکیل می دهند که می تواند به صورت خودآموز آموزش داده شود.
لایه های گرافیکی متفاوت
در ادامه ، برخی از قابلیت های موجود در گرافیک TensorFlow این تور جامع نیست. برای کسب اطلاعات بیشتر از Github ما دیدن کنید تا امکانات جدیدی را که TensorFlow Graphics در اختیار شما قرار می دهد ، بیابید. در تصویر زیر ، فرمالیسم زاویه محور برای چرخاندن یک مکعب استفاده شده است. محور چرخش به سمت بالا است و زاویه آن مثبت است و مکعب را در جهت خلاف جهت عقربه های ساعت می چرخاند. در این مثال Colab ، ما نشان می دهیم که چگونه فرمالیسم های چرخشی را می توان در یک شبکه عصبی آموزش داد که برای پیش بینی چرخش و ترجمه یک شی مشاهده شده آموزش دیده است. این وظیفه هسته اصلی بسیاری از برنامه ها از جمله روبات هایی است که بر تعامل با محیط خود تمرکز می کنند. در این سناریوها ، گرفتن اشیاء (به عنوان مثال توسط دسته آنها) با بازوی روباتیک نیاز به برآورد دقیق موقعیت این اجسام نسبت به بازو دارد.

مدل سازی دوربین ها
مدل های دوربین نقش بسزایی در بینایی کامپیوتر دارندبر ظاهر اجسام سه بعدی که بر روی صفحه تصویر نمایش داده می شود تأثیر می گذارد. همانطور که در زیر مشاهده می شود ، به نظر می رسد که مکعب در حال بزرگ شدن و پایین آمدن است ، در حالی که در واقعیت این تغییرات فقط به دلیل تغییر در فاصله کانونی است. این مثال Colab را برای جزئیات بیشتر در مورد مدل های دوربین و یک مثال مشخص از نحوه استفاده از آنها در TensorFlow امتحان کنید.

مواد
مدل های مواد نحوه تعامل نور با اجسام را مشخص می کنند تا ظاهر منحصر به فرد خود را به آنها بدهند. به عنوان مثال ، برخی از مواد مانند گچ نور را به طور یکنواخت در همه جهات منعکس می کنند ، در حالی که برخی دیگر مانند آینه ها کاملاً دیدنی هستند. در این دفترچه تعاملی Colab ، نحوه تولید رندرهای زیر را با استفاده از Tensorflow Graphics خواهید آموخت. همچنین این فرصت را خواهید داشت که با پارامترهای مواد و نور بازی کنید تا حس خوبی از نحوه تعامل آنها ایجاد شود. پیش بینی دقیق خواص مواد برای بسیاری از وظایف اساسی است. به عنوان مثال ، می تواند به کاربران این امکان را بدهد که مبلمان مجازی را در محیط خود رها کرده و قطعات را بصورت واقع بینانه با فضای داخلی خود ترکیب کرده و به کاربران درک دقیقی از ظاهر آن مبلمان بدهند.
هندسه-پیچیدگی های سه بعدی و یکپارچه سازی
در سال های اخیر ، سنسورهای خروجی سه بعدی داده ها به شکل ابرهای نقطه ای یا مشبک در حال تبدیل شدن به بخشی از زندگی روزمره ما هستند ، از سنسورهای عمق تلفن های هوشمند گرفته تا لیدارهای اتومبیل خودران. با توجه به ساختار نامنظم آنها ، پیوندهای روی این نمایش ها به طور قابل توجهی در مقایسه با تصاویری که ساختار شبکه معمولی را ارائه می دهند ، بسیار سخت تر است. TensorFlow Graphics دارای دو لایه کانولوشن سه بعدی و یک لایه جمع آوری سه بعدی است که به عنوان مثال به شبکه ها اجازه می دهد تا طبقه بندی بخش های معنایی را روی مشها انجام دهند ، همانطور که در زیر نشان داده شده و در این دفترچه Colab نشان داده شده است.
TensorBoard 3d
اشکال زدایی بصری یک راه عالی برای ارزیابی اینکه آیا یک آزمایش در حال انجام است یا خیر در جهت درست برای این منظور ، TensorFlow Graphics دارای یک افزونه TensorBoard است تا بصورت تعاملی مشهای سه بعدی و ابرهای نقطه ای را تجسم کند.
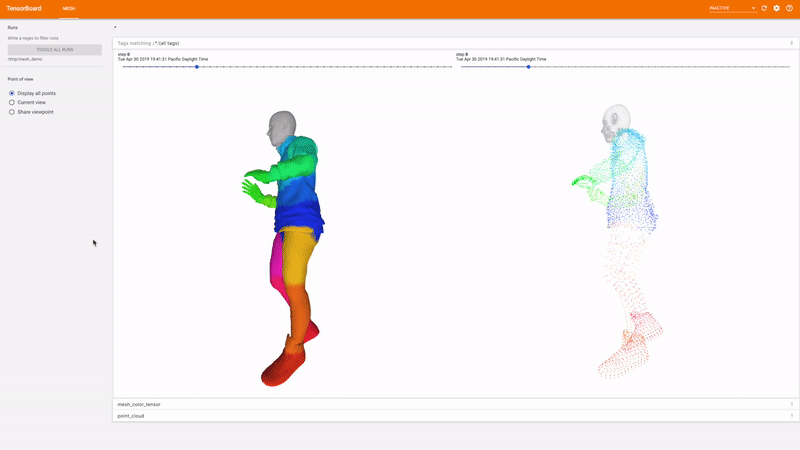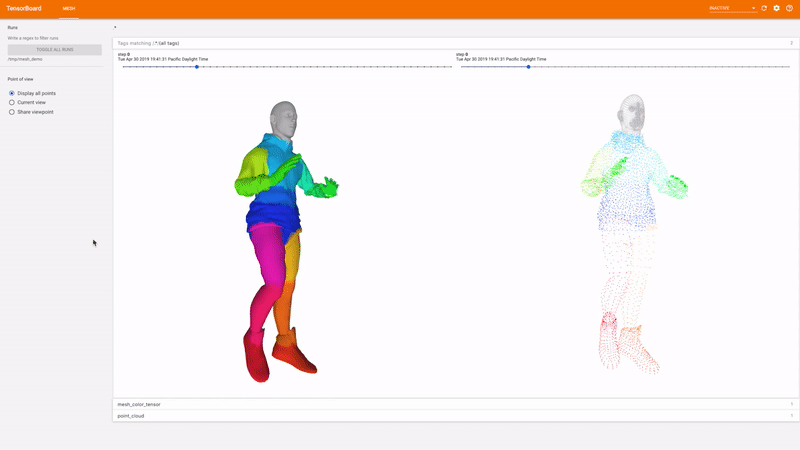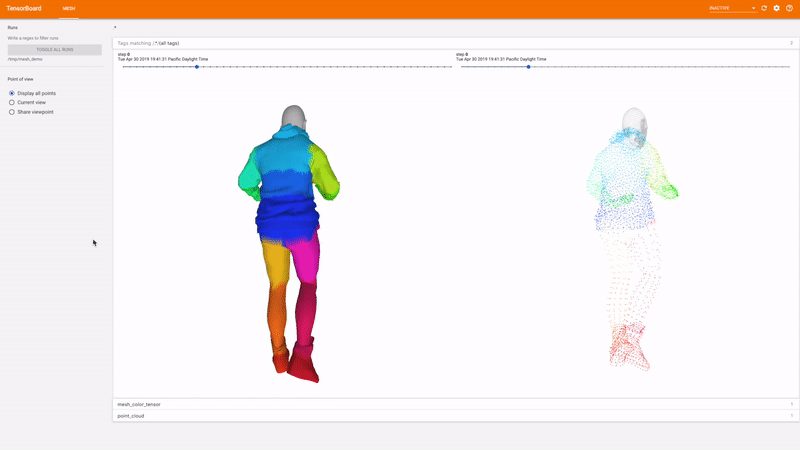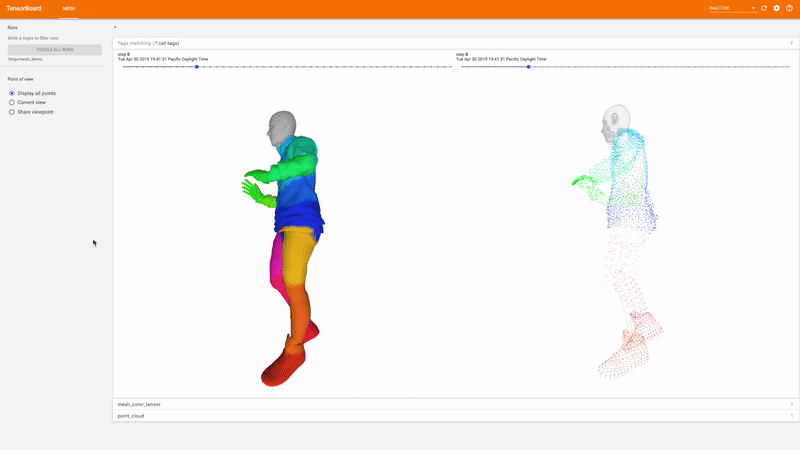
شروع کنید
اولین نسخه پشتیبانی از TensorFlow Graphics با TensorFlow 1.13.1 و بالاتر سازگار است. با مراجعه به https://www.tensorflow.org/graphics API و دستورالعمل های نصب کتابخانه را خواهید یافت .
تقدیرنامه
ایجاد گرافیک TensorFlow یک کار گروهی بود. تشکر ویژه از جم کسکین ، پاول پیدلیپنسکی ، آمیش ماکادیا و آونش سود که همگی سهم قابل توجهی داشتند.