خانه تکنولوژی
معرفی تکنولوژی روز دنیاخانه تکنولوژی
معرفی تکنولوژی روز دنیاI هوش مصنوعی - works شبکه های عصبی تحول برای برنامه های کامپیوتری بینایی (一)
I هوش مصنوعی - works شبکه های عصبی تحول برای برنامه های کامپیوتری بینایی (一)
CNN 原理 簡介 與 代表性 CNN 模型
p 分享 的 是 副研究員 他擅長 利用 機器 學習 打造 各種 如 物件 辨識، 影像 分割، 臉部 辨識، 動作 辨識، 人數 計算، 影像 比 對 等 電腦 視覺 應用. 從 論文 如數家珍 的 程度 看來، 林 副研究員 真的 在 此 領域 鑽研 甚深HOG ((از hypraptive)
對 HOG 有 興趣 深入 的 同學 , 參考 連結文章 , 內含 پایتون。 作。
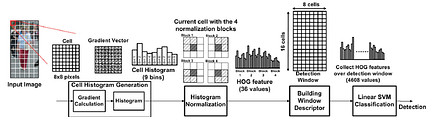 HOG 計算/> . 。。。。。。。。 p p p p p p p p p p p透過 大量 資料 的 訓練، 「自己 學習」 到 好的 特徵، 並 決定 好的 分類 器. 因 餵 進 大量 圖片 之後، 就 可以 產生 模型 跟 結果، 人類 專家 的 參與 越來越 少، 因此 又 可以 稱為پایان به پایان یادگیری。 (當然 實務 上 需要)) p p p p p p p p萃取 較低 階 的 特徵 (如 邊緣)، 接著 開始 辨識 出 如 車輪، 窗戶 等 比較 中 階 的 特徵، 最後 是 整個 車子 的 樣子. 當然، 實際上 模型 訓練 時 是 反向 的، 要 學好 高層 的 特徵。 中層 什麼 p p p p p p p p
HOG 計算/> . 。。。。。。。。 p p p p p p p p p p p透過 大量 資料 的 訓練، 「自己 學習」 到 好的 特徵، 並 決定 好的 分類 器. 因 餵 進 大量 圖片 之後، 就 可以 產生 模型 跟 結果، 人類 專家 的 參與 越來越 少، 因此 又 可以 稱為پایان به پایان یادگیری。 (當然 實務 上 需要)) p p p p p p p p萃取 較低 階 的 特徵 (如 邊緣)، 接著 開始 辨識 出 如 車輪، 窗戶 等 比較 中 階 的 特徵، 最後 是 整個 車子 的 樣子. 當然، 實際上 模型 訓練 時 是 反向 的، 要 學好 高層 的 特徵。 中層 什麼 p p p p p p p p  از Nvidia
از Nvidia (類 神經 網路 一個 一個 一個 ((一個 一個 一個 一個 一個 一個 一個 一個 一個 一個 一個 一個 一個 一個 一個 一個Con (به طور کامل متصل شده است) 所.
ural 深度 基礎 基礎 參考 筆記 p p p p
CNN Network شبکه عصبی کانولوشنال v v v v on on on on نقشه ویژگی) 來 提取 特徵 , 運作 如下 圖 p
 CNN 卷積 im
CNN 卷積 im Convolution 是 兩個 重點 概念 ivity اتصال محلی sharing اشتراک وزن connect connect اتصال محلی 是 指 在sharing sharing sharing sharing sharing sharing sharing sharing sharing sharing sharing sharing تقسیم وزن 是 用來 偵測 偵測
نقشه راه برای دید رایانه ای
نقشه راه برای دید رایانه ای
مقدمه ای بر مراحل اصلی تشکیل دهنده یک سیستم بینایی کامپیوتری. از نحوه پیش پردازش تصاویر ، استخراج ویژگی ها و پیش بینی ها شروع می شود.
 عکس توسط Ennio Dybeli در مورد Unsplash
عکس توسط Ennio Dybeli در مورد Unsplash مقدمه
دید کامپیوتر (CV) امروزه یکی از کاربردهای اصلی هوش مصنوعی است (به عنوان مثال تشخیص تصویر ، ردیابی اشیاء ، طبقه بندی چند برچسب). در این مقاله ، برخی از مراحل اصلی تشکیل دهنده یک سیستم بینایی رایانه ای را برای شما شرح می دهم. تصاویر وارد سیستم می شوند.
اکنون ما به طور مختصر برخی از فرایندهای اصلی را که ممکن است داده های ما در هر یک از این سه مرحله مختلف طی کنند ، مرور می کنیم.
تصاویر وارد سیستم < /h1>
هنگام تلاش برای پیاده سازی یک سیستم CV ، ما باید دو جزء اصلی را در نظر بگیریم: سخت افزار کسب تصویر و نرم افزار پردازش تصویر. یکی از الزامات اصلی که باید برای استقرار سیستم CV رعایت شود ، آزمایش استحکام آن است. در واقع سیستم ما باید بتواند در تغییرات محیطی (مانند تغییرات روشنایی ، جهت گیری ، مقیاس بندی) تغییر ناپذیر باشد و بتواند وظیفه طراحی شده خود را به طور مکرر انجام دهد. به منظور برآوردن این الزامات ، ممکن است لازم باشد محدودیت هایی را برای سخت افزار یا نرم افزار سیستم خود اعمال کنیم (به عنوان مثال کنترل از راه دور محیط روشنایی).
هنگامی که تصویری از دستگاه سخت افزاری ، روشهای زیادی برای نمایش عددی رنگها (Color Spaces) در یک سیستم نرم افزاری وجود دارد. دو مورد از مشهورترین فضاهای رنگی RGB (قرمز ، سبز ، آبی) و HSV (رنگ ، اشباع ، ارزش) هستند. یکی از مزایای اصلی استفاده از فضای رنگی HSV این است که فقط با گرفتن اجزای HS می توانیم روشنایی سیستم خود را ثابت نگه داریم (شکل 1).
 شکل 1: فضاهای رنگی RGB در مقابل HSV [1]
شکل 1: فضاهای رنگی RGB در مقابل HSV [1] استخراج کننده ویژگی
پیش پردازش تصویر
هنگامی که تصویری وارد سیستم می شود و با استفاده از یک فضای رنگی نمایش داده می شود ، می توانیم عملگرهای مختلف را بر روی تصویر اعمال کنیم تا نمای آن بهبود یابد:
 شکل 2: تکامل هسته
شکل 2: تکامل هسته پس از پردازش یک تصویر ، می توانیم تکنیک های پیشرفته تری را برای استخراج با استفاده از روش هایی مانند تشخیص درجه اول لبه (به عنوان مثال اپراتور Prewitt ، اپراتور Sobel ، Canny Edge Detector) و Hough Transforms ، لبه ها و اشکال درون یک تصویر را مشاهده می کنید.
استخراج ویژگی
یکبار قبل -پردازش یک تصویر ، 4 نوع اصلی مورفولوژی ویژگی وجود دارد که می توان با استفاده از Feature Extractor از یک تصویر استخراج کرد: از استخراج کننده ویژگی یک مثال ساده از یک ویژگی جهانی می تواند یک هیستوگرام از مقادیر پیکسل های ذخیره شده باشد.
پس از استخراج مجموعه ای از ویژگیهای متمایز ، می توانیم از آنها برای آموزش مدل یادگیری ماشین برای نتیجه گیری توصیف کننده های ویژگی را می توان به راحتی در پایتون با استفاده از کتابخانه هایی مانند OpenCV اعمال کرد. BoVW) به منظور ایجاد یک مجموعه از کلمات بصری ،ما قبل از هر چیز باید با استخراج همه ویژگی ها از مجموعه ای از تصاویر (به عنوان مثال با استفاده از ویژگی های مبتنی بر شبکه یا ویژگی های محلی) یک واژگان ایجاد کنیم. پی در پی ، می توانیم تعداد دفعاتی که یک ویژگی استخراج شده در یک تصویر ظاهر می شود را شمارش کرده و از نتایج یک هیستوگرام فرکانس بسازیم. با استفاده از هیستوگرام فرکانس به عنوان یک الگوی اصلی ، می توان در نهایت دسته بندی کرد که آیا یک تصویر متعلق به یک کلاس است یا نه با مقایسه هیستوگرام آنها (شکل 3).
این فرایند را می توان در چند مرحله زیر خلاصه کرد:
تصاویر جدید را می توان با تکرار همین فرایند برای هر تصویری که می خواهیم طبقه بندی کنیم و سپس با استفاده از هر الگوریتم طبقه بندی طبقه بندی کنیم تا دریابیم کدام تصویر در واژگان ما بیشتر شبیه آزمایش ما است تصویر.
 شکل 3: کیف واژه های بصری [2]
شکل 3: کیف واژه های بصری [2] امروزه به لطف ایجاد معماری شبکه های عصبی مصنوعی مانند Convolutional شبکه های عصبی (CNNs) و شبکه های عصبی مصنوعی مکرر (RCNNs) ، امکان ایجاد یک گردش کار جایگزین برای دید رایانه ای (شکل 4) وجود دارد.
 شکل 4: گردش کار بینایی کامپیوتر [3]
شکل 4: گردش کار بینایی کامپیوتر [3] در این حالت ، الگوریتم یادگیری عمیق هر دو مرحله استخراج ویژگی و طبقه بندی رایانه را در بر می گیرد. گردش کار بینایی هنگام استفاده از شبکه های عصبی کانولوشن ، هر لایه از شبکه عصبی تکنیک های مختلف استخراج ویژگی را در توضیحات خود اعمال می کند (به عنوان مثال ، لایه 1 لبه ها را تشخیص می دهد ، لایه 2 شکل هایی را در یک تصویر پیدا می کند ، لایه 3 تصویر را تقسیم می کند ، و غیره ...) قبل از ارائه ویژگی بردارهای طبقه بندی لایه متراکم.
برنامه های کاربردی دیگر یادگیری ماشین در بینایی رایانه ای شامل مناطقی مانند طبقه بندی چند برچسب و تشخیص اشیا می شود. در طبقه بندی چند برچسب ، ما قصد داریم مدلی بسازیم که بتواند به درستی تعداد اجسام موجود در یک تصویر را مشخص کند و به چه طبقه ای تعلق دارد. در عوض ، در تشخیص اشیاء ، هدف ما این است که این مفهوم را با شناسایی موقعیت اشیاء مختلف در تصویر ، گامی فراتر ببریم. جدیدترین مقالات و پروژه ها مرا در Medium دنبال کنید و در لیست پستی من مشترک شوید. اینها برخی از اطلاعات تماس های من است:
کتابشناسی
[1] ربات مدولار که به عنوان پاک کننده ساحل استفاده می شود ، Felippe Roza. دروازه تحقیق. قابل دسترسی در: https://www.researchgate.net/figure/RGB-left-and-HSV-right-color-spaces_fig1_310474598
[2] مجموعه ای از کلمات بصری در گروه OpenCV ، Vision & Graphics. یان کوندراک. قابل دسترسی در: https://vgg.fiit.stuba.sk/2015-02/bag-of-visual-words-in-opencv/
[3] Deep Learning Vs. دید رایانه ای سنتی. Haritha Thilakarathne ، NaadiSpeaks. قابل دسترسی در: https://naadispeaks.wordpress.com/2018/08/12/deep-learning-vs-traditional-computer-vision/
از دو صفحه کامپیوتر به یک-آموزش زندگی با کمتر.
از دو صفحه کامپیوتر به یک-آموزش زندگی با کمتر.
 اعتبار تصویر: Unsplash /PolaroMagnet
اعتبار تصویر: Unsplash /PolaroMagnet گاهی اوقات چیزی خارق العاده در مورد زندگی کشف می کنید که به طور تصادفی اتفاق می افتد. این همان چیزی است که برای من اتفاق افتاد.
چهار سال پیش من در یک ساختمان اداری قدیمی در حومه شهر کار می کردم. کار من این بود که محصولات مالی را خانه به خانه بفروشم. در اولین روزم ، متوجه شدم که همه میزها فقط یک صفحه کامپیوتر دارند. به.
شما به آن عادت می کنید.
دوازده ماه سریع جلو بیایید و من یک صفحه نمایش حرفه ای بودم و از آن خوشحال بودم.
من می روم هر روز به دفتر بروید و لپ تاپ را به یک صفحه وصل کنید. من میانبرهای صفحه کلید را آموخته بودم تا با تفاوت کار بر روی یک صفحه نمایش در مقایسه با دو صفحه آشنا شوم.
وقتی به روزرسانی رایانه خانگی خود را انجام دادم دوباره تصمیم گرفتم و تصمیم گرفتم Mac دیگری با دو صفحه دیگر نخرم حرفه ای ، و در عوض ، به دنبال iMac بسیار ارزان تر باشید. اجرای دو صفحه روی iMac آسان نبود و هزینه بر بود - بعلاوه ، دیگر فضای میز برای دو صفحه وجود نداشت.
مطمئناً تغییر از دو صفحه کامپیوتر در خانه به یک صفحه نمایش پس از چند ماه آسان شد. در اوایل سال جاری ، من کار جدیدی را شروع کردم و س oldال قدیمی "یک صفحه یا دو صفحه ، آقا" هنگامی که برای اولین بار با بخش IT ملاقات کردم ، مطرح شد.

من با یک لبخند بزرگ و مطمئن گفتم "من یک صفحه نمایش می گیرم ، مامان"
همکاران من که در حال گوش دادن به مکالمه بودند گیج شده بودند.
چرا کمتر انتخاب می کنید؟
این همان چیزی بود که همکاران من در حال فکر کردن بودند در حالی که آنها تماشا می کردند که من آنچه را که به عنوان تصور می کردم رها می کنم. امتیاز بزرگ و اصرار بر یک صفحه کامپیوتر. آنها فکر کردند من مخالف آن چیزی هستم که من تبلیغ می کنم. من نبودم. و کتابهایی که در آن زمان می خواندم در مورد روند جدیدی از خوردن لوبیا و برنج به مدت یک هفته در ماه صحبت می کردند. این ممکن است پوچ به نظر برسد ، اما یک دلیل خوب در پشت آن وجود دارد: این به شما کمک می کند زندگی کمتری را بیاموزید.
 اعتبار تصویر: Betty Crocker
اعتبار تصویر: Betty Crocker خوردن غذاهای ساده مانند لوبیا و برنج به شما می آموزد که بدون پیچیدگی هایی مانند آشپزها در برنامه تلویزیونی Master Chef آشپزی کنید.
خوردن غذاهای ساده به شما می آموزد که نیازی به چاشنی ، سس ، شراب ، چاشنی یا هر چیز دیگری ندارید.
دلیل انتخاب یک صفحه کامپیوتر این است که من را همه کاره کرده است و من مجبور بودم کارهای کمتر را کمتر یاد بگیرم. من همیشه در محیطی کار نمی کنم که دارای دو صفحه نمایش باشد و بتوانم آن را به لپ تاپ وصل کنم.
وقتی در تعطیلات در ساحل نشسته اید دو صفحه وجود ندارد.
< p> اگر برای راه اندازی اولیه کار کنید و کار کنید ، احتمالاً دو صفحه نمایش نخواهید داشت.شاید من کارم را از دست بدهم. شاید دوباره شرکت خودم را راه اندازی کنم. شاید من از خانه کار می کردم جایی که دو صفحه وجود نداشت. من انعطاف پذیرتر شدم.
داشتن کمتر باعث می شود قدر همه چیز را بیشتر بدانید.
داشتن یک صفحه باعث شد قدر کارهای بیشتری را که می توانم در آن صفحه انجام دهم درک کنم. من دیگر 1000 زبانه باز نداشتم زیرا فقط یک صفحه برای کار کردن داشتم. وقتی می خواستم یک پست وبلاگ بنویسم ، فقط یک پنجره روی صفحه من وجود داشت ، باز.
صفحه دوم بی نظمی و حواس پرتی بود در حالی که زندگی یک صفحه روی یک چیز متمرکز بود. من از هر کلمه روی آن صفحه جدا قدردانی کردم و میز کار من فوق العاده زیبا به نظر می رسید زیرا فقط یک چیز روی آن وجود داشت.
قدردانی از همه چیز در زندگی با این ایده شروع می شود که دیگر نیازی به آن ندارید. شما به مقدار کمتری نیاز دارید.
فراخوان به عمل
اگر می خواهید بهره وری خود را افزایش داده و نکات ارزشمندی در زندگی بیاموزید ، پس در لیست پستی خصوصی من مشترک شوید. شما همچنین کتاب الکترونیکی رایگان من را دریافت خواهید کرد که به شما کمک می کند تا به صورت آنلاین به یک تأثیرگذار تغییر دهنده بازی تبدیل شوید.
همین حالا برای عضویت اینجا را کلیک کنید!
ماشین ها و جادو: آموزش کامپیوتر برای نوشتن هری پاتر
ماشین ها و جادو: آموزش کامپیوتر برای نوشتن هری پاتر
 منبع : http://nicolesnovelreads.blogspot.com/2015/12/ranking-harry-potter-books-and-films.html
منبع : http://nicolesnovelreads.blogspot.com/2015/12/ranking-harry-potter-books-and-films.htmlمن فی نفسه چیزی در برابر نمایش ندارم. من همانقدر برای هری پاتر و کودک نفرین شده بسیار هیجان زده هستم که هزاره بعدی که شبها از پنجره بیرون خیره شده بود و منتظر نامه آنها از هاگوارتز بود ، بسیار هیجان زده شد ، اما با آنچه می توان تصور کرد تحویل جغد ناکارآمد است گمراه شد. سرویس. فقط چیزی در مورد جادوی کتاب ها وجود دارد که دست نیافتنی به نظر می رسد - غیر قابل تکرار.
با توجه به گفته های من ، به افتخار نمایشنامه آینده ، سعی می کنم کمی از این جادو را بازسازی کنم.
مدل های زبانی جنبه ای اساسی در پردازش زبان طبیعی (NLP) هستند که سعی می کنند توزیع احتمالی را در دنباله های کلمات بیاموزند ، به گونه ای که - با توجه به سابقه متن قبلی - بتوانند جملات جدید ، یک کلمه در یک زمان ایجاد کنند. ، کاملا از ابتدا در دنیای واقعی ، آنها در همه چیز از تشخیص گفتار گرفته تا بازیابی اطلاعات استفاده می شوند. در دنیای ما ، آنها به ما در بازنویسی هری پاتر کمک می کنند.
بخش بعدی به بررسی اجمالی جادوی پشت شبکه های عصبی ، LSTM و جاسازی کلمات که ما را تشکیل می دهند ، می پردازد. مدل زبان ، و پس از آن ما مستقیماً وارد The Good Stuff می شویم.
یادگیری عمیق برای مدل سازی زبان
من سعی می کنم این توضیحات را در سطح بالا و تا آنجا که ممکن است غیر فنی باشد ، بنابراین هرکسی که از قبل با این نظریه آشنایی دارد (یا علاقه ای به آن ندارد) می تواند با خیال راحت از این بخش صرف نظر کند.
یادگیری ماشینی 90 درصد از معجزات تکنولوژیکی را که در اطراف می بینید و می شنوید ، تقویت می کند. هر روز ، از جمله اتومبیل های خودران ، Siri ، تشخیص تقلب در کارت اعتباری ، موتورهای توصیه آمازون و Netflix ، و اخیراً حتی خود گوگل را نیز جستجو کنید. البته ، تقریباً 100٪ از این سیستم ها شامل مواردی فراتر از یادگیری ماشین می شود ، اما بعداً به آن می پردازیم. الگوریتمی که در اصل برای تقلید از مغز انسان طراحی شده است: سیگنال های ورودی ، سلول های عصبی که به این سیگنال ها واکنش نشان می دهند و خروجی هایی که اطلاعات را به سایر نورون ها منتقل می کند.
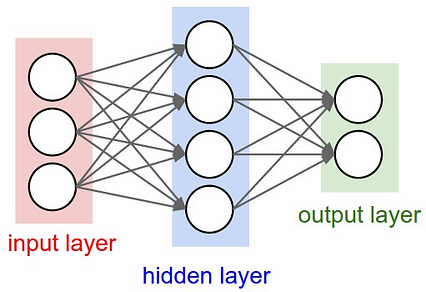 یک شبکه عصبی وانیلی. منبع: http: //cs231n.github.io،/neural-networks-1/
یک شبکه عصبی وانیلی. منبع: http: //cs231n.github.io،/neural-networks-1/ در علوم کامپیوتر ، این به مجموعه ای از مقادیر ورودی ، یک یا چند لایه مخفی برای نگهداری محاسبات متوسط ، ترجمه می شود ، لایه خروجی و یک سری وزنه که هر نورون را از یک لایه به لایه دیگر متصل می کند. این وزنه ها ، که از داده ها توسط رایانه "آموخته می شود" (در فرایند آن وارد نمی شوم ، اما در اصل نسخه ای از حدس و بررسی + حساب است) ، قرار است اهمیت هر نورون را با احترام نشان دهد. تا در نهایت تصمیم درست را اعلام کند یادگیری عمیق ، که اخیراً با عنوان "آینده هوش مصنوعی" مورد توجه قرار گرفته است ، واقعاً شامل انواع مختلف شبکه عصبی اساسی با چندین لایه پنهان است.
بله ، می دانم. عمیق به معنای عمیق است - بسیاری از لایه های پنهان. خودشه. هر دوی ما می توانیم خودروهای خودران خود را بسازیم.تعدادی از محدودیت های مهم به عنوان مثال ، فقط می تواند با ورودی و خروجی با طول ثابت کار کند. با این حال ، تعداد زیادی از وظایف را نمی توان با آن محدودیت ها بیان کرد. برای مثال ترجمه ماشینی را در نظر بگیرید-چگونه باید جملات ورودی و خروجی با طول متغیر را به دو زبان مختلف در نظر بگیریم و آنها را در یک شبکه عصبی معمولی قرار دهیم؟
پاسخ: ما اینطور نیستیم. اینجاست که RNN وارد شده است.
RNN یا شبکه های عصبی مکرر برای رفع این نقص دقیق طراحی شده اند. توالی مدل RNN در اساسی ترین سطح خود: مجموعه ای از تصاویر ، صداها ، کلمات و غیره ، جایی که (1) ترتیب نمایش هر عنصر در سری اهمیت دارد و (2) محاسبه یکسان روی هر عنصر انجام می شود .
در نتیجه ، RNN دقیقاً شبیه یک شبکه عصبی معمولی است ، مگر با یک "حلقه" مستقل در لایه مخفی که محاسبه را برای هر عنصر تکرار می کند.
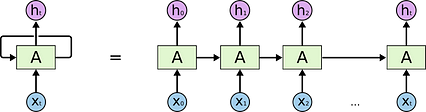 شبکه عصبی مکرر ، در طول زمان باز می شود (راست). X منبع: http://colah.github.io/posts/2015-08-Understanding-LSTMs/
شبکه عصبی مکرر ، در طول زمان باز می شود (راست). X منبع: http://colah.github.io/posts/2015-08-Understanding-LSTMs/محاسبه نورون در هر مرحله نه تنها ورودی ها و وزنهای فوری را در نظر می گیرد ، بلکه تاریخچه ورودی ها و محاسبات گذشته ، به منظور تعیین مرحله منطقی بعدی. (اگر علاقمند هستید ، این دانشمندان MIT را که با پیشگیری از نظریه بیگ بنگ و دفتر ، مدل پیش بینی رفتار انسان را آموزش داده اند ، بررسی کنید. و فکر می کنید بعد از کار حوصله تان سر رفته است.)
با استفاده از RNN ، که می تواند در طول زمان "محو" شود تا محاسبات را در هر تکرار لایه (های) پنهان انجام دهد ، در نهایت می توانیم ساخت مدل زبانی خود را آغاز کنیم. آنچه من در واقع از آن استفاده کردم یک LSTM (حافظه کوتاه مدت بلند) RNN بود ، نوعی از مدل اصلی RNN که برخی از کاستی های اساسی آن را در برخورد با توالی های طولانی (به عنوان مثال شیب ناپدید شدن و انفجار) برطرف می کند. من قصد ندارم در اینجا به آنها بپردازم ، اما پست وبلاگ colah در مورد آنها کاملاً فوق العاده است. در اصل ، هر واحد توسط مجموعه ای از دروازه های "ورودی" ، "فراموش کردن" و "به روز رسانی" تنظیم می شود که به شبکه اجازه می دهد جریان اطلاعات را کنترل کند.
جاسازی کلمات
قبل از پرداختن به برخی از متن های سرگرم کننده که مدل زبان هری پاتر ایجاد کرده است ، می خواهم به طور مختصر در مورد یکی از بخشهای جالب پروژه صحبت کنم: جاسازی کلمات.
ایده ساده است. جمله ای را که می خواهیم به مدل خود وارد کنیم ، در نظر بگیرید: "هری از تخت بلند شد." برای اینکه دستگاه آن را به عنوان ورودی پردازش کند ، هر کلمه باید به نوعی معادل عددی منحصر به فرد کدگذاری شود. یک رویکرد ساده لوحانه این است که به سادگی تمام کلمات موجود در واژگان منبع را یک به یک شمارش کنید ، یعنی "هری" = 1 ، "got" = 2 و غیره. با این حال ، همانطور که می توانید تصور کنید ، این امر بسیاری از اطلاعات نحوی را حذف می کند. در مورد کلمات و روابط بین آنها با این رویکرد ، "هری" به همان اندازه از "رون" متمایز است که "هری" برای "پرواز" است.
راه حل؟ هر کلمه را در یک فضای بردار آموخته و با ابعاد بالا قرار دهید ، جایی که کلمات از نظر معنی به هم نزدیک هستند ، به همین ترتیب در فضای بردار نزدیک هستند. به عبارت دیگر ، کامپیوتر را آموزش دهید تا به طور محاسباتی معنی کلمات را درک کند.
این جاسازی ها عبارتند ازهمچنین توسط یک شبکه عصبی ، با استفاده از معماری CBOW (کیسه پیوسته کلمات) یا پرش از گرامر ، آموخته شده است و در هر صورت نتایج بسیار شگفت انگیزی به ما می دهند. به عنوان مثال ، حتی یک فرد ابتدایی قادر است معناشناسی روابط و کثرت جنسیت را به تصویر بکشد:
 جاسازی کلمه در فضای بردار همانطور که در یک فضای کم بعدی تجسم شده است. منبع: http://datascientistdiary.blogspot.com/
جاسازی کلمه در فضای بردار همانطور که در یک فضای کم بعدی تجسم شده است. منبع: http://datascientistdiary.blogspot.com/در مدل زبانی زیر ، هر کلمه از هفت رمان هری پاتر به یک جاسازی با ابعاد بالا تبدیل شد که به موازات پارامترها آموخته شد- یا وزنه - در حین تمرین.
مطالب خوب
اگر قسمت قبلی را رد کرده اید (یا به احتمال زیاد خواندن آن را شروع کرده اید و حوصله تان سر رفته است) ، در اینجا دوباره خواندن را شروع می کنید.
دو ویژگی خاص این قطعه از متن وجود داشت که یادگیری آن را بسیار مشکل می کرد:
… و…
بنابراین ... بله. همانطور که گفتم ، جی کی رولینگ به این زودی جایگزین نمی شود.
با توجه به مشکلاتی که در بالا ذکر کردم ، چند مورد وجود دارد که مدل بسیار خوب انجام داد:
(+) این سبک کلی نگارش را انتخاب کرد (البته بدون اینکه بتوانم واقعاً بنویسم). توزیع طول جمله ، طول پاراگراف ، ساختارهای گفتگو ، موجودیت ها و حتی نحوه معرفی و بسته شدن دیالوگ ("هرمیون با صراحت گفت" یا "با عصبی از هری پرسید") همه به درستی تکرار شده است.
(+) گرامر (نوعی) آموخته است. به طور خاص ، جملات-در حالی که غالباً از نظر معنایی مضحک هستند-به طور کلی بسیار نزدیک به نحو درست هستند (به عنوان مثال انتخاب کلمه اشتباه اما بخش صحیح گفتار). به به طور خاص ، این قسمت ایجاد شده را بررسی کنید:
به احساس عمومی و لحن پشت گذر توجه کنید ، و به کلماتی که به آن کمک می کنند توجه کنید. "صورت سرد و کم رنگ" ، "صدای خشن" ، "لرز" ، "صدای تکان دهنده" ، "وحشتناک" ، "دوست نداشتن زیاد" ، - همه آنها بسیار شوم ، درست است؟ به عبارت دیگر ، دستگاه یاد گرفته است که لحن خاصی از کلمات را حداقل تا حدی تفسیر کرده و حفظ کند.
البته از سوی دیگر ، مدل دارای چندین اشکال آشکار است: /p>
(-) بیشتر آن معنی ندارد. *Shrug*
(-) مدل حافظه بلند مدت قابل تشخیص ندارد. به این معنا که حتی وقتی جملات معنا پیدا می کنند ، برای تشکیل یک داستان دور هم جمع نمی شوند. در حالی که RNN ها از لحاظ نظری قادر به ساختن توالی هایی با هر طول هستند (اگرچه این مدل خاص در طول ورودی پنجاه کلمه محدود شده بود) ، حتی نوع LSTM نمی تواند حس طولانی مدت کافی برای ساختن "رویدادها" را به شیوه ای منسجم به تصویر بکشد. .
(-) مدل ضمایر و مقدمات را نمی فهمد. بسیاری از مسائل مربوط به "خود ارجاع" وجود دارد ، مانند:
پس این همه به چه معناست؟
 تصادف اشتباه است ، من می دانم. منبع: https://memegenerator.net/instance/38831271
تصادف اشتباه است ، من می دانم. منبع: https://memegenerator.net/instance/38831271داستان کوتاه: تولید خودکار متن سخت است.
جدا از دریافتاین پروژه برای تولید برخی از متن های بسیار خنده دار به سبک نویسندگان مشهور (به عنوان مثال وقتی در شکسپیر آموزش دیده بود ، همان مدل لورد ویلوبی را از لوسنتیو به عنوان "آقا ، الاغ مهربان من" یاد می کرد) ، این پروژه به عنوان یک مطالعه موردی خوب عمل می کند. برای برخی از موانع اساسی در هوش مصنوعی مدرن امیدوارم در پست بعدی با آنها آشنا شوم ، اما در عین حال ، کد این پروژه در اختیار شما قرار می گیرد ، که می توانید از آن برای تکرار مقدار بی نهایت متن نامفهوم هری پاتر در اوقات فراغت خود استفاده کنید.
تشکر فراوان از پست اصلی وبلاگ شرجیلوزیر و آندره کارپاتی در مورد این موضوع به عنوان الهام. برنامه نویسی مبارک و درود بر J. K. Rowling.
 از خواندن آن لذت بردید؟ روی ❤ زیر کلیک کنید تا آن را به سایر خوانندگان علاقه مند توصیه کنید! > img src = "https://cdn-images-1.medium.com/max/426/1*Mro-phkgJv4rZQ223OYosA.jpeg">
از خواندن آن لذت بردید؟ روی ❤ زیر کلیک کنید تا آن را به سایر خوانندگان علاقه مند توصیه کنید! > img src = "https://cdn-images-1.medium.com/max/426/1*Mro-phkgJv4rZQ223OYosA.jpeg"> 

نحوه کار رایانه ها را بیاموزید
نحوه کار رایانه ها را بیاموزید
یکی از بزرگترین نقایص دانش که ما در بین مهندسان خودآموخته و فارغ التحصیلان bootcamp مشاهده می کنیم ، در زمینه معماری کامپیوتر است. در حالی که اکثر مهندسان می دانند که باید الگوریتم ها و ساختار داده ها را بیاموزند ، بسیاری از شنیدن اینکه درک چیزی در حد معماری رایانه می تواند بسیار ارزشمند باشد شگفت زده می شوند.
خوشبختانه بسیاری از موارد عالی وجود دارد. منابعی برای یادگیری در مورد کام آرش وجود دارد و با کمی فداکاری و راهنمایی می توانید مقدار زیادی از آنچه را که دانستن ارزشمند است به خودتان آموزش دهید. امیدوارم این مقاله شما را در مسیر درست آغاز کند.

چرا این را بیاموزید؟
ممکن است بدون درک سخت افزاری که در نهایت کد شخص بر روی آن اجرا می شود ، یک توسعه دهنده وب موفق باشید. متأسفانه ، غفلت از معماری رایانه ، نوع مهندسی را که یک مهندس می تواند انجام دهد ، به سه دلیل محدود می کند: به به سادگی لایه های غیرمستقیم کمتری وجود دارد که در غیر این صورت نادیده گرفتن توسعه دهنده از سخت افزار را بهانه می کند.
ثانیاً ، نوشتن نرم افزار سریع بدون درک نحوه دسترسی به داده ها و اجرای کد غیرممکن است. این امر به ویژه در حال حاضر اهمیت دارد که دسترسی به حافظه اصلی صدها برابر کندتر از اجرای یک دستورالعمل است ... بی توجهی به سلسله مراتب حافظه به احتمال زیاد علت مشکلات عملکرد است ، همانطور که مایک اکتون در صحبت cppcon خود به طور قانع کننده استدلال کرد.
ثالثاً ، همه چکیده های بین سخت افزار و زبانهای سطح بالا نشتی دارند. بسیاری از مفاهیم در برنامه نویسی سطح بالا از آنالوگهای برنامه نویسی سطح پایین نشأت می گیرد که به نوبه خود مفاهیم سطح پایین را نیز به راحتی حل می کند. هیچکدام از این انتزاعات پاک نیستند. اکثر آنها به عنوان راحتی ایجاد شده اند ، نه پارادایم های کاملاً جدیدی که به برنامه نویسان اجازه می دهد در مورد موارد زیر فکر نکنند. این درست است که آیا برنامه نویسان سطح بالا آن را درک کرده اند یا نه ، بنابراین نادیده گرفتن مبانی می تواند هم گران باشد و هم تعجب آور. هنگامی که ما در مورد "یک عدد صحیح" ، یا متغیر "تخصیص" صحبت می کنیم ، یا از طریق مرجع یا مقدار عبور می کنیم ، یا یک مقدار را روی "پشته" قرار می دهیم ، اینها مفاهیمی هستند که دارای میراث و مفاهیم سخت افزاری هستند. مهندسانی که این مبانی را بیشتر درک می کنند ، کار بهتری نسبت به کسانی که نمی دانند ، انجام می دهند.
اهداف شما
در اینجا فرض می کنیم که انگیزه شما برای یادگیری معماری کامپیوتر این است که یک مهندس نرم افزار م effectiveثرتر شوید. به اگر هدف شما مهندس کامپیوتر شدن است (یعنی حل مشکلات با طراحی سخت افزار) ، این راهنما کافی نخواهد بود ، و ما اکیداً توصیه می کنیم که یک مسیر معمول مهندسی کامپیوتر را دنبال کنید.
اگر از پیشنهادات ما پیروی کنید. ، شما در نهایت باید به همان سطح از معماری کامپیوتر فارغ التحصیل از یک برنامه CS برتر در مقطع کارشناسی برسید. این امر نه تنها شما را به عنوان یک مهندس نرم افزار سطح بالا م effectiveثرتر می کند ، بلکه در صورت تمایل به مهندسی نرم افزارهای سطح پایین تر نیز مجهز می شوید.
آنچه خواهید آموخت
هر رایانه دوره یا منبع معماری اهداف متفاوتی خواهد داشت. از دیدگاه ما ، اطمینان از این مطالب به این معنی است که می توانید به این س questionsالات به طور کامل پاسخ دهید:
یک دوره واحد
اگر سادگی یک دوره آموزشی خوب را ترجیح می دهید ، ما 61C "ایده های عالی در معماری رایانه" برکلی را توصیه می کنیم. این دوره بین مدلهای ساده شده مورد نیاز برای شروع به فکر کردن در مورد معماری کامپیوتر و برخی از پیچیدگی های واقعی معماری مدرن ، تعادل مناسبی برقرار می کند.
یادداشت ها و آزمایشگاه های سخنرانی به صورت آنلاین در دسترس هستند ، و سخنرانی های گذشته در YouTube هستند. به متن همراه پیشنهادی سازمان و طراحی رایانه ای پترسون و هنسی است که هم عالی است و هم معمولاً مورد استفاده قرار می گیرد. همه مطالب عالی است ؛ هیچ سخنرانی ای وجود ندارد که ما پیشنهاد کنیم آن را کنار بگذارید. سیستم های محاسباتی ، که با نام "Nand2Tetris" نیز شناخته می شود ، کتابی بلندپروازانه است که سعی می کند درک منسجمی از نحوه عملکرد همه چیز در رایانه از منطق بولی تا برنامه های کوچک به شما ارائه دهد. هر فصل شامل ساختن قطعه کوچکی از سیستم کلی ، از نوشتن دروازه های منطقی ابتدایی در HDL ، از طریق CPU و اسمبلر ، تا برنامه ای به اندازه بازی Tetris است.
این نیمه اول این کتاب و همه پروژه ها به صورت رایگان از وب سایت Nand2Tetris موجود است. همچنین به عنوان یک دوره Coursera همراه با ویدئوهای موجود در دسترس است.
توصیه ما این است که شش فصل اول کتاب را بخوانید و پروژه ها را (تا شامل مونتاژ کننده و شامل) کامل کنید. انجام این کار درک شما را از رابطه بین معماری ماشین و نرم افزاری که بر روی آن کار می کند ، تقویت می کند.
به نظر ما نیمه دوم کتاب به اندازه کتاب اول قانع کننده نیست. حتی در نیمه اول ، Nand2Tetris با مبادله عمق به انسجام خود می رسد. به طور خاص ، دو مفهوم بسیار مهم در معماری رایانه ای مدرن خط لوله و سلسله مراتب حافظه هستند ، اما هر دو بیشتر در متن وجود ندارند. پیشنهاد می کنیم به جای ادامه فرایند مونتاژ به 61 درجه روی بیاورید.
برای کسانی که 61C را بسیار آسان می دانند یا مایلند در برخی از محتواها عمیق تر بکشند ، CS 162 را پیشنهاد می کنیم ، یک پیشرفته تر. دوره معماری کامپیوتر نیز در برکلی. CS 162 همچنین بردارها و پردازنده های گرافیکی را عمیق تر پوشش می دهد ، بنابراین توصیه می کنیم اگر در زمینه توسعه بسیار امیدوار کننده هستید ، از طریق آن سخنرانی ها کار کنید.
منابع متفرقه
برای کسانی که خواهان یک راهپیمایی ملایم تر و معمولی تر تا معماری رایانه هستند ، یکی از کتابهایی که معمولاً توصیه می شود "کد چارلز پتزولد" است. ما فکر می کنیم خوب است. ما فقط آن را پیشنهاد می کنیم اگر به دنبال برخی از آنها هستیدخواندن سبک تر یا احساس می کنید به زمان نیاز دارید تا بتوانید با ایده مطالعه کام کام آشنا شوید. Nand2Tetris بسیار قابل دسترسی است بنابراین ما عموماً پیشنهاد می کنیم که مستقیماً به آنجا بروید.
در انتهای دیگر طیف ، مقاله دان لوئو در CPU ها از دهه 80 چه جدید است و اولریش درپرر آنچه هر برنامه نویس باید درباره حافظه بداند هر دو شگفت انگیز هستند هر دوی آنها مفاهیم فوق را تصور می کنند ، اما به طور کلی قابل دسترسی هستند و درک شما از معماری رایانه را از دو منظر متفاوت اما متمرکز بر تمرین کنندگان پیش می برند.
در نهایت ، ما یک مسیر مونتاژ MIPS را به exerciseism.io اضافه کرده ایم. برای سهولت تمرین نوشتن مجمع برای مردم. انجام این کار یک راه ارزشمند برای کشف رابط سخت افزار/نرم افزار است و یادگیری مجموعه MIPS به طور خاص یک یا دو هفته از محتوای 61C را تشکیل می دهد.
به غواصی عمیق تر علاقه دارید؟ بردفیلد هر 2-3 ماه یک دوره معماری کامپیوتر و رابط سخت افزار/نرم افزار را اجرا می کند.