خانه تکنولوژی
معرفی تکنولوژی روز دنیاخانه تکنولوژی
معرفی تکنولوژی روز دنیامقدمه ای بر بینایی کامپیوتر
مقدمه ای بر بینایی کامپیوتر
 عکس سگ من ، پدینگتون ، با محدودیت جعبه هایی که برگها را نشان می دهند قطعاً خوراکی نیستند. (تصویر Roboflow.)
عکس سگ من ، پدینگتون ، با محدودیت جعبه هایی که برگها را نشان می دهند قطعاً خوراکی نیستند. (تصویر Roboflow.) بینایی رایانه می تواند انقلابی در جهان ایجاد کند. تا کنون ، بینایی رایانه ای به انسان کمک کرده است تا مشکلات زیادی را حل کند ، مانند کاهش ترافیک و نظارت بر سلامت محیط.
 تصاویر یک راکون جذاب ، لنی ، با حاشیه نویسی جعبه. (تصویر Roboflow.)
تصاویر یک راکون جذاب ، لنی ، با حاشیه نویسی جعبه. (تصویر Roboflow.) از لحاظ تاریخی ، برای انجام بینایی کامپیوتری ، به یک پیش زمینه فنی واقعا قوی نیاز داشتید. پس از خواندن این پست ، باید درک خوبی از بینایی کامپیوتر بدون پیش زمینه فنی قوی داشته باشید و باید مراحل لازم برای حل مشکل بینایی رایانه را بدانید.
بینایی کامپیوتر چیست؟
< p> در یک مفهوم اساسی ، بینایی رایانه ای این توانایی را دارد که یک کامپیوتر بتواند آنچه را که شبیه انسان است ببیند و درک کند.وقتی می خواهید از یک لیوان آب یک نوشیدنی بخورید ، چندین موارد مرتبط با بینایی اتفاق می افتد:
بینایی کامپیوتر یک چیز مشابه است ... اما برای رایانه ها!
مشکلات بینایی کامپیوتر در چند سطل مختلف قرار می گیرد. این مهم است زیرا مشکلات مختلف با روش های مختلف حل می شوند.
انواع مختلف مشکلات بینایی رایانه چیست؟
 انواع مشکلات بینایی رایانه. اقتباس از دوره استنفورد CS 231N. (تصویر Roboflow.)
انواع مشکلات بینایی رایانه. اقتباس از دوره استنفورد CS 231N. (تصویر Roboflow.) شش نوع مشکل بینایی رایانه وجود دارد که چهار مورد از آنها در تصویر بالا نشان داده شده است.
 Roboflow این تصویر را به عنوان اتوبوس مدرسه و نه تاکسی ، واگن برقی یا چیز دیگری به درستی تشخیص می دهد. (تصویر Roboflow.)
Roboflow این تصویر را به عنوان اتوبوس مدرسه و نه تاکسی ، واگن برقی یا چیز دیگری به درستی تشخیص می دهد. (تصویر Roboflow.)  GIF دود آتش سوزی در حال تشخیص است. (منبع تصویر.)
GIF دود آتش سوزی در حال تشخیص است. (منبع تصویر.)  تشخیص نوتروفیل ها ، نوعی گلبول سفید خون که نقش کلیدی در سیستم ایمنی بدن حیوانات دارد. (اعتبار: Matro Sokac ؛ مجاز به استفاده.)
تشخیص نوتروفیل ها ، نوعی گلبول سفید خون که نقش کلیدی در سیستم ایمنی بدن حیوانات دارد. (اعتبار: Matro Sokac ؛ مجاز به استفاده.)  اعمال تقسیم بندی معنایی بر روی تصویر سه نفر در دوچرخه. (منبع اصلی.)
اعمال تقسیم بندی معنایی بر روی تصویر سه نفر در دوچرخه. (منبع اصلی.)  اعمال تشخیص کلید واژه برای پنج نفر. (منبع تصویر.)
اعمال تشخیص کلید واژه برای پنج نفر. (منبع تصویر.) چگونه می توانم مشکلات بینایی کامپیوتر را حل کنم؟
اگر می خواهید رایانه شما به شما در حل مشکلات مربوط به داده ها کمک کند ، معمولاً یک سری مراحل را دنبال می کنید. همین امر در مورد مشکلات بینایی رایانه صادق است ، مگر اینکه مراحل کمی متفاوت به نظر برسند.
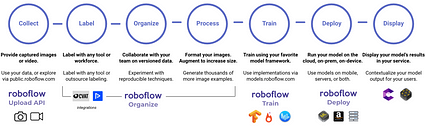 یک فرآیند هفت مرحله ای برای حل مشکلات بینایی رایانه. (تصویر Roboflow.)
یک فرآیند هفت مرحله ای برای حل مشکلات بینایی رایانه. (تصویر Roboflow.) ما هر یک از این مراحل را طی می کنیم ، با این هدف که در پایان فرآیند مراحل مورد نیاز برای حل مشکل بینایی کامپیوتر و همچنین یک مشکل خوب را بدانید. نمای کلی رایانه.
 سه تصویر از آبراهام لینکلن. (منبع اصلی.)
سه تصویر از آبراهام لینکلن. (منبع اصلی.) اگر هدف شما این است که رایانه خود را بشناسید تا بفهمد سگ ها چگونه به نظر می رسند ، پس کامپیوتر به شما نیاز دارد که به او بگویید کدام پیکسل ها مربوط به یک سگ است! اینجاست که تصویر خود را برچسب گذاری یا حاشیه نویسی می کنید. در زیر تصویری از مجموعه داده مادون قرمز حرارتی است که به طور فعال در حال حاشیه نویسی است. یک جعبه محدود کننده در اطراف فرد کشیده شده و یک جعبه محدود کننده جداگانه در اطراف سگ کشیده شده است. این کار توسط یک انسان انجام می شود. (از آنجا که این تصویر دارای بیش از یک شیء است و از کادرهای محدود کننده استفاده می کند ، می دانیم که این تصویر برای یک کار تشخیص شی استفاده می شود!) این کادرهای محدود کننده از طریق ابزاری به نام Microsoft VoTT یا ابزار برچسب گذاری ویژوال شی اضافه می شوند. < /p> 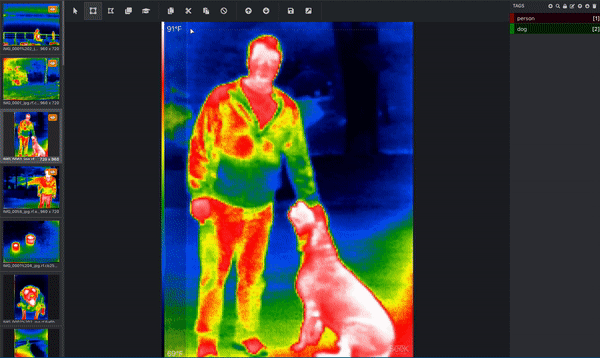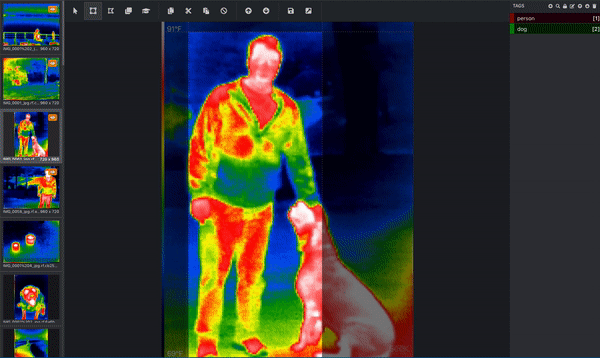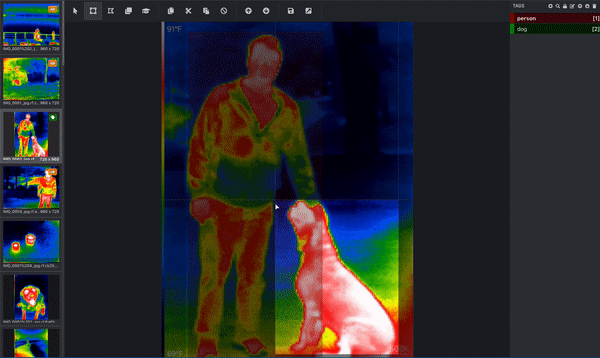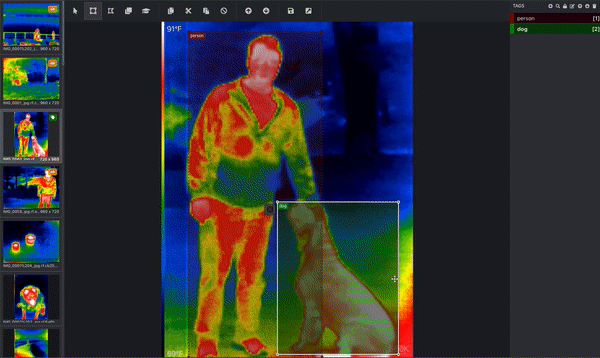 حاشیه نویسی تصویر با Microsoft VoTT ؛ ما یک آغازگر در مورد نحوه استفاده از VoTT نوشتیم. (تصویر Roboflow.)
حاشیه نویسی تصویر با Microsoft VoTT ؛ ما یک آغازگر در مورد نحوه استفاده از VoTT نوشتیم. (تصویر Roboflow.)
این تنها ابزار نیست - شما می توانید از ابزارهای دیگر مانند CVAT (Computer Vision Annotation Tool) ، برنامه وب Roboflow یا خود API بارگذاری ما استفاده کنید.
هنگامی که داده ها را جمع آوری کردید و ابزار خود را برای برچسب گذاری انتخاب کردید ، شروع به برچسب زدن می کنید! شما باید سعی کنید تا آنجا که می توانید تصاویر را برچسب گذاری کنید. اگر تعداد تصاویر شما بیش از آن چیزی است که می توانید برچسب گذاری کنید ، در اینجا چند استراتژی یادگیری فعال برای برچسب زدن موثرتر تصاویر آمده است.
 برخی مراحل رایج پیش پردازش و افزایش تصویر در Roboflow موجود است. (تصویر Roboflow.)
برخی مراحل رایج پیش پردازش و افزایش تصویر در Roboflow موجود است. (تصویر Roboflow.) همچنین می توانید کاری به نام افزایش تصویر انجام دهید. این کمی متفاوت است - این فقط بر تصاویری که شما برای آموزش مدل خود استفاده می کنید (نحوه مشاهده کامپیوتر را آموزش دهید) تأثیر می گذارد. در یک جمله ، بزرگنمایی تصویر تغییرات کوچکی در تصاویر شما ایجاد می کند به طوری که حجم نمونه شما (تعداد تصاویر) افزایش می یابد و به احتمال زیاد تصاویر شما منعکس کننده شرایط دنیای واقعی هستند. به عنوان مثال ، می توانید جهت تصویر خود را به طور تصادفی تغییر دهید. بگویید با تلفن خود از یک کامیون عکس می گیرید. اگر رایانه آن تصویر دقیق را ببیند ، ممکن است کامیون را تشخیص دهد. اگر رایانه تصویری مشابه از یک کامیون را مشاهده کرد که با دست کسی چند درجه چرخانده شده است ، ممکن است رایانه تشخیص کامیون را دشوارتر کند. افزودن مراحل تقویت ، حجم نمونه شما را با ایجاد کپی از تصاویر اصلی و سپس کمی مزاحمت برای آنها افزایش می دهد تا مدل شما دیدگاه های دیگری را نیز ببیند.
 نمی توانم در مورد سگها صحبت کنم و تصویری از سگ من ، پدینگتون ندارم! (تصویر توسط نویسنده.)
نمی توانم در مورد سگها صحبت کنم و تصویری از سگ من ، پدینگتون ندارم! (تصویر توسط نویسنده.) روشهای مختلفی وجود دارد که ما می توانیم میزان رایانه ما را به خوبی تشخیص دهیم.
مدلهای مختلفی وجود دارد که می توانند برای مشکلات تصویر استفاده شود ، اما رایج ترین (و معمولاً بهترین عملکرد!) شبکه عصبی پیچشی است. اگر از یک شبکه عصبی متغیر استفاده می کنید ، بدانید که بسیاری از قضاوت ها در معماری مدل وارد شده اند که بر قدرت دیدن رایانه شما تأثیر می گذارد! خوشبختانه برای ما ، تعداد زیادی معماری مدل از پیش تعیین شده وجود دارد که برای مشکلات مختلف بینایی رایانه بسیار خوب عمل می کند.
 یک مدل تشخیص شیء YOLOv5 که پیش بینی های زمان واقعی را با دوچرخه ، ماشین و شخص ایجاد می کند. (تصویر Roboflow.)
یک مدل تشخیص شیء YOLOv5 که پیش بینی های زمان واقعی را با دوچرخه ، ماشین و شخص ایجاد می کند. (تصویر Roboflow.) ممکن است بخواهید مدل خود را در برنامه ای قرار دهید ، بنابراین رایانه شما می تواند پیش بینی ها را در زمان واقعی مستقیماً از تلفن شما ایجاد کند! ممکن است بخواهید به برنامه ای در رایانه خود ، یا به AWS ، یا چیزی داخلی در تیم خود بپردازید. ما قبلاً به طور مفصل در مورد یکی از روشهای استقرار مدل بینایی رایانه در اینجا نوشتیم. اگر حداقل کمی با Python و API ها آشنا هستید ، این مستندات در مورد استنباط در بینایی رایانه می تواند مفید باشد!
صرف نظر از مراحل بعدی شما ، کار انجام نمی شود اینجا کاملاً تمام نمی شود! کاملاً مستند است که مدلهایی که به خوبی روی تصاویری که به آن می دهید کار می کنند ، ممکن است با گذشت زمان بدتر کار کنند. (ما برخی از تحقیقات گوگل در مورد این مشکل عملکرد مدل را مطالعه کردیم و نکات مهم ما را شرح دادیم.) با این حال ، ما امیدواریم که شما به این نتیجه رسیده اید که به هدفی که در ابتدای این پست نوشتیم رسیده اید:
از اینکه تا اینجا با ما همراه بودید متشکریم! هرگونه سوال یا منابع اضافی که در نظرات دارید به ما اطلاع دهید - و اگر چیزی در ارتباط با بینایی رایانه ایجاد می کنید ، خوشحال می شویم ببینیم شما چه کار می کنید!
در ابتدا در https: //blog.roboflow منتشر شده است .com در 23 نوامبر 2020.
نقشه راه برای دید رایانه ای
نقشه راه برای دید رایانه ای
مقدمه ای بر مراحل اصلی تشکیل دهنده یک سیستم بینایی کامپیوتری. از نحوه پیش پردازش تصاویر ، استخراج ویژگی ها و پیش بینی ها شروع می شود.
 عکس توسط Ennio Dybeli در مورد Unsplash
عکس توسط Ennio Dybeli در مورد Unsplash مقدمه
دید کامپیوتر (CV) امروزه یکی از کاربردهای اصلی هوش مصنوعی است (به عنوان مثال تشخیص تصویر ، ردیابی اشیاء ، طبقه بندی چند برچسب). در این مقاله ، برخی از مراحل اصلی تشکیل دهنده یک سیستم بینایی رایانه ای را برای شما شرح می دهم. تصاویر وارد سیستم می شوند.
اکنون ما به طور مختصر برخی از فرایندهای اصلی را که ممکن است داده های ما در هر یک از این سه مرحله مختلف طی کنند ، مرور می کنیم.
تصاویر وارد سیستم < /h1>
هنگام تلاش برای پیاده سازی یک سیستم CV ، ما باید دو جزء اصلی را در نظر بگیریم: سخت افزار کسب تصویر و نرم افزار پردازش تصویر. یکی از الزامات اصلی که باید برای استقرار سیستم CV رعایت شود ، آزمایش استحکام آن است. در واقع سیستم ما باید بتواند در تغییرات محیطی (مانند تغییرات روشنایی ، جهت گیری ، مقیاس بندی) تغییر ناپذیر باشد و بتواند وظیفه طراحی شده خود را به طور مکرر انجام دهد. به منظور برآوردن این الزامات ، ممکن است لازم باشد محدودیت هایی را برای سخت افزار یا نرم افزار سیستم خود اعمال کنیم (به عنوان مثال کنترل از راه دور محیط روشنایی).
هنگامی که تصویری از دستگاه سخت افزاری ، روشهای زیادی برای نمایش عددی رنگها (Color Spaces) در یک سیستم نرم افزاری وجود دارد. دو مورد از مشهورترین فضاهای رنگی RGB (قرمز ، سبز ، آبی) و HSV (رنگ ، اشباع ، ارزش) هستند. یکی از مزایای اصلی استفاده از فضای رنگی HSV این است که فقط با گرفتن اجزای HS می توانیم روشنایی سیستم خود را ثابت نگه داریم (شکل 1).
 شکل 1: فضاهای رنگی RGB در مقابل HSV [1]
شکل 1: فضاهای رنگی RGB در مقابل HSV [1] استخراج کننده ویژگی
پیش پردازش تصویر
هنگامی که تصویری وارد سیستم می شود و با استفاده از یک فضای رنگی نمایش داده می شود ، می توانیم عملگرهای مختلف را بر روی تصویر اعمال کنیم تا نمای آن بهبود یابد:
 شکل 2: تکامل هسته
شکل 2: تکامل هسته پس از پردازش یک تصویر ، می توانیم تکنیک های پیشرفته تری را برای استخراج با استفاده از روش هایی مانند تشخیص درجه اول لبه (به عنوان مثال اپراتور Prewitt ، اپراتور Sobel ، Canny Edge Detector) و Hough Transforms ، لبه ها و اشکال درون یک تصویر را مشاهده می کنید.
استخراج ویژگی
یکبار قبل -پردازش یک تصویر ، 4 نوع اصلی مورفولوژی ویژگی وجود دارد که می توان با استفاده از Feature Extractor از یک تصویر استخراج کرد: از استخراج کننده ویژگی یک مثال ساده از یک ویژگی جهانی می تواند یک هیستوگرام از مقادیر پیکسل های ذخیره شده باشد.
پس از استخراج مجموعه ای از ویژگیهای متمایز ، می توانیم از آنها برای آموزش مدل یادگیری ماشین برای نتیجه گیری توصیف کننده های ویژگی را می توان به راحتی در پایتون با استفاده از کتابخانه هایی مانند OpenCV اعمال کرد. BoVW) به منظور ایجاد یک مجموعه از کلمات بصری ،ما قبل از هر چیز باید با استخراج همه ویژگی ها از مجموعه ای از تصاویر (به عنوان مثال با استفاده از ویژگی های مبتنی بر شبکه یا ویژگی های محلی) یک واژگان ایجاد کنیم. پی در پی ، می توانیم تعداد دفعاتی که یک ویژگی استخراج شده در یک تصویر ظاهر می شود را شمارش کرده و از نتایج یک هیستوگرام فرکانس بسازیم. با استفاده از هیستوگرام فرکانس به عنوان یک الگوی اصلی ، می توان در نهایت دسته بندی کرد که آیا یک تصویر متعلق به یک کلاس است یا نه با مقایسه هیستوگرام آنها (شکل 3).
این فرایند را می توان در چند مرحله زیر خلاصه کرد:
تصاویر جدید را می توان با تکرار همین فرایند برای هر تصویری که می خواهیم طبقه بندی کنیم و سپس با استفاده از هر الگوریتم طبقه بندی طبقه بندی کنیم تا دریابیم کدام تصویر در واژگان ما بیشتر شبیه آزمایش ما است تصویر.
 شکل 3: کیف واژه های بصری [2]
شکل 3: کیف واژه های بصری [2] امروزه به لطف ایجاد معماری شبکه های عصبی مصنوعی مانند Convolutional شبکه های عصبی (CNNs) و شبکه های عصبی مصنوعی مکرر (RCNNs) ، امکان ایجاد یک گردش کار جایگزین برای دید رایانه ای (شکل 4) وجود دارد.
 شکل 4: گردش کار بینایی کامپیوتر [3]
شکل 4: گردش کار بینایی کامپیوتر [3] در این حالت ، الگوریتم یادگیری عمیق هر دو مرحله استخراج ویژگی و طبقه بندی رایانه را در بر می گیرد. گردش کار بینایی هنگام استفاده از شبکه های عصبی کانولوشن ، هر لایه از شبکه عصبی تکنیک های مختلف استخراج ویژگی را در توضیحات خود اعمال می کند (به عنوان مثال ، لایه 1 لبه ها را تشخیص می دهد ، لایه 2 شکل هایی را در یک تصویر پیدا می کند ، لایه 3 تصویر را تقسیم می کند ، و غیره ...) قبل از ارائه ویژگی بردارهای طبقه بندی لایه متراکم.
برنامه های کاربردی دیگر یادگیری ماشین در بینایی رایانه ای شامل مناطقی مانند طبقه بندی چند برچسب و تشخیص اشیا می شود. در طبقه بندی چند برچسب ، ما قصد داریم مدلی بسازیم که بتواند به درستی تعداد اجسام موجود در یک تصویر را مشخص کند و به چه طبقه ای تعلق دارد. در عوض ، در تشخیص اشیاء ، هدف ما این است که این مفهوم را با شناسایی موقعیت اشیاء مختلف در تصویر ، گامی فراتر ببریم. جدیدترین مقالات و پروژه ها مرا در Medium دنبال کنید و در لیست پستی من مشترک شوید. اینها برخی از اطلاعات تماس های من است:
کتابشناسی
[1] ربات مدولار که به عنوان پاک کننده ساحل استفاده می شود ، Felippe Roza. دروازه تحقیق. قابل دسترسی در: https://www.researchgate.net/figure/RGB-left-and-HSV-right-color-spaces_fig1_310474598
[2] مجموعه ای از کلمات بصری در گروه OpenCV ، Vision & Graphics. یان کوندراک. قابل دسترسی در: https://vgg.fiit.stuba.sk/2015-02/bag-of-visual-words-in-opencv/
[3] Deep Learning Vs. دید رایانه ای سنتی. Haritha Thilakarathne ، NaadiSpeaks. قابل دسترسی در: https://naadispeaks.wordpress.com/2018/08/12/deep-learning-vs-traditional-computer-vision/