خانه تکنولوژی
معرفی تکنولوژی روز دنیاخانه تکنولوژی
معرفی تکنولوژی روز دنیامقدمه ای بر بینایی کامپیوتر
مقدمه ای بر بینایی کامپیوتر
 عکس سگ من ، پدینگتون ، با محدودیت جعبه هایی که برگها را نشان می دهند قطعاً خوراکی نیستند. (تصویر Roboflow.)
عکس سگ من ، پدینگتون ، با محدودیت جعبه هایی که برگها را نشان می دهند قطعاً خوراکی نیستند. (تصویر Roboflow.) بینایی رایانه می تواند انقلابی در جهان ایجاد کند. تا کنون ، بینایی رایانه ای به انسان کمک کرده است تا مشکلات زیادی را حل کند ، مانند کاهش ترافیک و نظارت بر سلامت محیط.
 تصاویر یک راکون جذاب ، لنی ، با حاشیه نویسی جعبه. (تصویر Roboflow.)
تصاویر یک راکون جذاب ، لنی ، با حاشیه نویسی جعبه. (تصویر Roboflow.) از لحاظ تاریخی ، برای انجام بینایی کامپیوتری ، به یک پیش زمینه فنی واقعا قوی نیاز داشتید. پس از خواندن این پست ، باید درک خوبی از بینایی کامپیوتر بدون پیش زمینه فنی قوی داشته باشید و باید مراحل لازم برای حل مشکل بینایی رایانه را بدانید.
بینایی کامپیوتر چیست؟
< p> در یک مفهوم اساسی ، بینایی رایانه ای این توانایی را دارد که یک کامپیوتر بتواند آنچه را که شبیه انسان است ببیند و درک کند.وقتی می خواهید از یک لیوان آب یک نوشیدنی بخورید ، چندین موارد مرتبط با بینایی اتفاق می افتد:
بینایی کامپیوتر یک چیز مشابه است ... اما برای رایانه ها!
مشکلات بینایی کامپیوتر در چند سطل مختلف قرار می گیرد. این مهم است زیرا مشکلات مختلف با روش های مختلف حل می شوند.
انواع مختلف مشکلات بینایی رایانه چیست؟
 انواع مشکلات بینایی رایانه. اقتباس از دوره استنفورد CS 231N. (تصویر Roboflow.)
انواع مشکلات بینایی رایانه. اقتباس از دوره استنفورد CS 231N. (تصویر Roboflow.) شش نوع مشکل بینایی رایانه وجود دارد که چهار مورد از آنها در تصویر بالا نشان داده شده است.
 Roboflow این تصویر را به عنوان اتوبوس مدرسه و نه تاکسی ، واگن برقی یا چیز دیگری به درستی تشخیص می دهد. (تصویر Roboflow.)
Roboflow این تصویر را به عنوان اتوبوس مدرسه و نه تاکسی ، واگن برقی یا چیز دیگری به درستی تشخیص می دهد. (تصویر Roboflow.)  GIF دود آتش سوزی در حال تشخیص است. (منبع تصویر.)
GIF دود آتش سوزی در حال تشخیص است. (منبع تصویر.)  تشخیص نوتروفیل ها ، نوعی گلبول سفید خون که نقش کلیدی در سیستم ایمنی بدن حیوانات دارد. (اعتبار: Matro Sokac ؛ مجاز به استفاده.)
تشخیص نوتروفیل ها ، نوعی گلبول سفید خون که نقش کلیدی در سیستم ایمنی بدن حیوانات دارد. (اعتبار: Matro Sokac ؛ مجاز به استفاده.)  اعمال تقسیم بندی معنایی بر روی تصویر سه نفر در دوچرخه. (منبع اصلی.)
اعمال تقسیم بندی معنایی بر روی تصویر سه نفر در دوچرخه. (منبع اصلی.)  اعمال تشخیص کلید واژه برای پنج نفر. (منبع تصویر.)
اعمال تشخیص کلید واژه برای پنج نفر. (منبع تصویر.) چگونه می توانم مشکلات بینایی کامپیوتر را حل کنم؟
اگر می خواهید رایانه شما به شما در حل مشکلات مربوط به داده ها کمک کند ، معمولاً یک سری مراحل را دنبال می کنید. همین امر در مورد مشکلات بینایی رایانه صادق است ، مگر اینکه مراحل کمی متفاوت به نظر برسند.
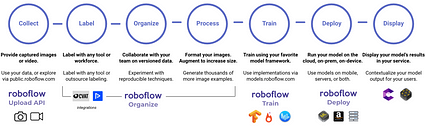 یک فرآیند هفت مرحله ای برای حل مشکلات بینایی رایانه. (تصویر Roboflow.)
یک فرآیند هفت مرحله ای برای حل مشکلات بینایی رایانه. (تصویر Roboflow.) ما هر یک از این مراحل را طی می کنیم ، با این هدف که در پایان فرآیند مراحل مورد نیاز برای حل مشکل بینایی کامپیوتر و همچنین یک مشکل خوب را بدانید. نمای کلی رایانه.
 سه تصویر از آبراهام لینکلن. (منبع اصلی.)
سه تصویر از آبراهام لینکلن. (منبع اصلی.) اگر هدف شما این است که رایانه خود را بشناسید تا بفهمد سگ ها چگونه به نظر می رسند ، پس کامپیوتر به شما نیاز دارد که به او بگویید کدام پیکسل ها مربوط به یک سگ است! اینجاست که تصویر خود را برچسب گذاری یا حاشیه نویسی می کنید. در زیر تصویری از مجموعه داده مادون قرمز حرارتی است که به طور فعال در حال حاشیه نویسی است. یک جعبه محدود کننده در اطراف فرد کشیده شده و یک جعبه محدود کننده جداگانه در اطراف سگ کشیده شده است. این کار توسط یک انسان انجام می شود. (از آنجا که این تصویر دارای بیش از یک شیء است و از کادرهای محدود کننده استفاده می کند ، می دانیم که این تصویر برای یک کار تشخیص شی استفاده می شود!) این کادرهای محدود کننده از طریق ابزاری به نام Microsoft VoTT یا ابزار برچسب گذاری ویژوال شی اضافه می شوند. < /p> 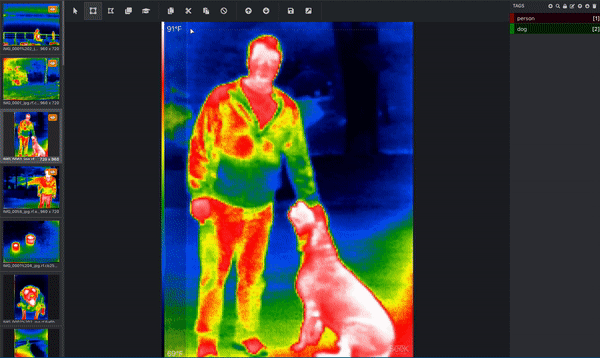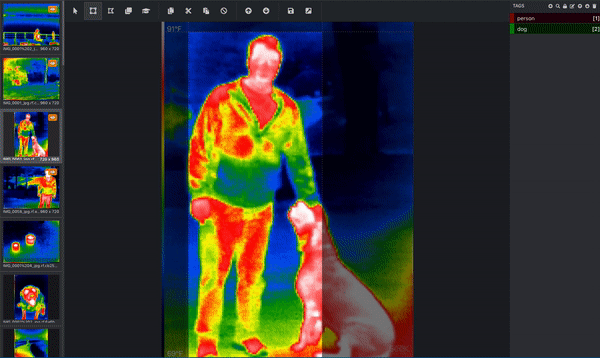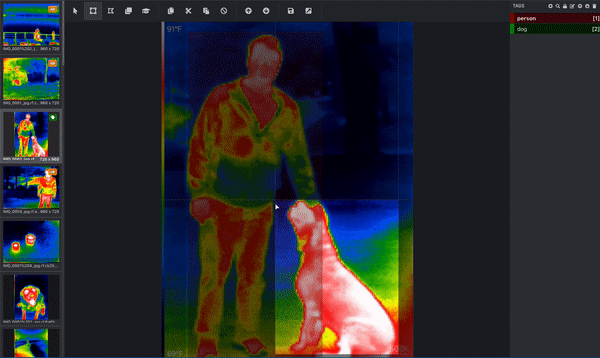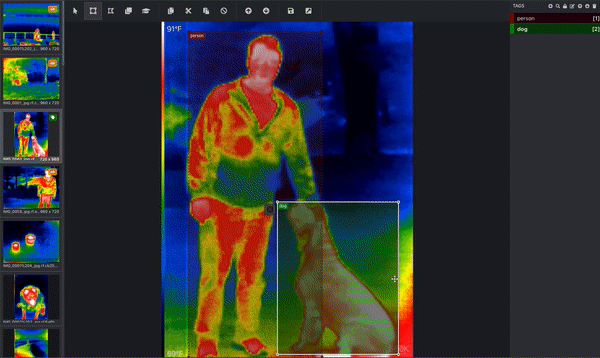 حاشیه نویسی تصویر با Microsoft VoTT ؛ ما یک آغازگر در مورد نحوه استفاده از VoTT نوشتیم. (تصویر Roboflow.)
حاشیه نویسی تصویر با Microsoft VoTT ؛ ما یک آغازگر در مورد نحوه استفاده از VoTT نوشتیم. (تصویر Roboflow.)
این تنها ابزار نیست - شما می توانید از ابزارهای دیگر مانند CVAT (Computer Vision Annotation Tool) ، برنامه وب Roboflow یا خود API بارگذاری ما استفاده کنید.
هنگامی که داده ها را جمع آوری کردید و ابزار خود را برای برچسب گذاری انتخاب کردید ، شروع به برچسب زدن می کنید! شما باید سعی کنید تا آنجا که می توانید تصاویر را برچسب گذاری کنید. اگر تعداد تصاویر شما بیش از آن چیزی است که می توانید برچسب گذاری کنید ، در اینجا چند استراتژی یادگیری فعال برای برچسب زدن موثرتر تصاویر آمده است.
 برخی مراحل رایج پیش پردازش و افزایش تصویر در Roboflow موجود است. (تصویر Roboflow.)
برخی مراحل رایج پیش پردازش و افزایش تصویر در Roboflow موجود است. (تصویر Roboflow.) همچنین می توانید کاری به نام افزایش تصویر انجام دهید. این کمی متفاوت است - این فقط بر تصاویری که شما برای آموزش مدل خود استفاده می کنید (نحوه مشاهده کامپیوتر را آموزش دهید) تأثیر می گذارد. در یک جمله ، بزرگنمایی تصویر تغییرات کوچکی در تصاویر شما ایجاد می کند به طوری که حجم نمونه شما (تعداد تصاویر) افزایش می یابد و به احتمال زیاد تصاویر شما منعکس کننده شرایط دنیای واقعی هستند. به عنوان مثال ، می توانید جهت تصویر خود را به طور تصادفی تغییر دهید. بگویید با تلفن خود از یک کامیون عکس می گیرید. اگر رایانه آن تصویر دقیق را ببیند ، ممکن است کامیون را تشخیص دهد. اگر رایانه تصویری مشابه از یک کامیون را مشاهده کرد که با دست کسی چند درجه چرخانده شده است ، ممکن است رایانه تشخیص کامیون را دشوارتر کند. افزودن مراحل تقویت ، حجم نمونه شما را با ایجاد کپی از تصاویر اصلی و سپس کمی مزاحمت برای آنها افزایش می دهد تا مدل شما دیدگاه های دیگری را نیز ببیند.
 نمی توانم در مورد سگها صحبت کنم و تصویری از سگ من ، پدینگتون ندارم! (تصویر توسط نویسنده.)
نمی توانم در مورد سگها صحبت کنم و تصویری از سگ من ، پدینگتون ندارم! (تصویر توسط نویسنده.) روشهای مختلفی وجود دارد که ما می توانیم میزان رایانه ما را به خوبی تشخیص دهیم.
مدلهای مختلفی وجود دارد که می توانند برای مشکلات تصویر استفاده شود ، اما رایج ترین (و معمولاً بهترین عملکرد!) شبکه عصبی پیچشی است. اگر از یک شبکه عصبی متغیر استفاده می کنید ، بدانید که بسیاری از قضاوت ها در معماری مدل وارد شده اند که بر قدرت دیدن رایانه شما تأثیر می گذارد! خوشبختانه برای ما ، تعداد زیادی معماری مدل از پیش تعیین شده وجود دارد که برای مشکلات مختلف بینایی رایانه بسیار خوب عمل می کند.
 یک مدل تشخیص شیء YOLOv5 که پیش بینی های زمان واقعی را با دوچرخه ، ماشین و شخص ایجاد می کند. (تصویر Roboflow.)
یک مدل تشخیص شیء YOLOv5 که پیش بینی های زمان واقعی را با دوچرخه ، ماشین و شخص ایجاد می کند. (تصویر Roboflow.) ممکن است بخواهید مدل خود را در برنامه ای قرار دهید ، بنابراین رایانه شما می تواند پیش بینی ها را در زمان واقعی مستقیماً از تلفن شما ایجاد کند! ممکن است بخواهید به برنامه ای در رایانه خود ، یا به AWS ، یا چیزی داخلی در تیم خود بپردازید. ما قبلاً به طور مفصل در مورد یکی از روشهای استقرار مدل بینایی رایانه در اینجا نوشتیم. اگر حداقل کمی با Python و API ها آشنا هستید ، این مستندات در مورد استنباط در بینایی رایانه می تواند مفید باشد!
صرف نظر از مراحل بعدی شما ، کار انجام نمی شود اینجا کاملاً تمام نمی شود! کاملاً مستند است که مدلهایی که به خوبی روی تصاویری که به آن می دهید کار می کنند ، ممکن است با گذشت زمان بدتر کار کنند. (ما برخی از تحقیقات گوگل در مورد این مشکل عملکرد مدل را مطالعه کردیم و نکات مهم ما را شرح دادیم.) با این حال ، ما امیدواریم که شما به این نتیجه رسیده اید که به هدفی که در ابتدای این پست نوشتیم رسیده اید:
از اینکه تا اینجا با ما همراه بودید متشکریم! هرگونه سوال یا منابع اضافی که در نظرات دارید به ما اطلاع دهید - و اگر چیزی در ارتباط با بینایی رایانه ایجاد می کنید ، خوشحال می شویم ببینیم شما چه کار می کنید!
در ابتدا در https: //blog.roboflow منتشر شده است .com در 23 نوامبر 2020.
نحوه درخواست برای تحصیلات تکمیلی علوم کامپیوتر

نحوه درخواست برای تحصیلات تکمیلی علوم کامپیوتر
در فکر درخواست برای Ph.D. در علوم کامپیوتر؟ در اینجا نحوه تعیین محل درخواست ، یافتن مشاوران بالقوه و تهیه برنامه کاربردی قوی وجود دارد.
شاید به این فکر افتاده اید که برای دکتری اقدام کنید. برنامه های علوم کامپیوتر قبل از تصمیم به پر کردن همه…
Inside Conflux: چگونه یک افسانه علوم کامپیوتر در حال برنامه ریزی برای حل بزرگترین چالش در جهان بلاک چین است
Inside Conflux: چگونه یک افسانه علوم کامپیوتر در حال برنامه ریزی برای حل بزرگترین چالش در جهان بلاک چین است

دیروز ، گروهی از سرمایه گذاران برجسته مانند Sequoia China ، Baidu Ventures ، مبادله رمزنگاری Huobi ، Metastable و IMO Ventures اعلام کردند که 35 میلیون دلار بودجه برای بنیاد Conflux ، سازمانی که پروتکل جدید بلندپروازانه ای را ایجاد می کند که با محدودیت های مقیاس پذیری فناوری های بلاک چین مقابله می کند. Conflux توسط گروهی از دانشمندان علوم کامپیوتر از دانشگاه تورنتو و دانشگاه Tsinghua چین رهبری می شود که شامل دکتر اندرو چی-چی یائو ، برنده جایزه تورینگ است. دکتر یائو که از افسانه های علوم رایانه محسوب می شود ، اخیراً به جنبه های مختلفی از ارزهای رمزنگاری شده مانند مشوق ها یا اجماع پرداخته است. برخی از این کارها منجر به یک مقاله تحقیقاتی شد که اصول اولیه زنجیره Conflux را بیان می کند.
Conflux جدیدترین افزودنی در زمینه فعال فناوری های دفتر کل توزیع شده است که تلاش می کند برخی از محدودیت های مقیاس پذیری بلاک چین را برطرف کند. مانند اتریوم یا بیت کوین. Dfinity ، Hasgraph ، Zilliqa ، Algorand از برجسته ترین پروژه هایی هستند که روی این حوزه متمرکز شده اند. ایده های پشت Conflux شباهت هایی با برخی از این پروژه ها دارد اما به مدل اجماع ناکاموتو وفادار می ماند. از نظر مفهومی ، پروتکل Conflux بر اساس مدل پیاپی Nakamoto با اجماع برای تولید یک بلوک در آن زمان به شبکه اجازه می دهد تا تعدادی دلخواه از بلوک های همزمان را بدون قربانی شدن تغییرناپذیری بلاک چین ایجاد کند. از نظر فنی ، این بهینه سازی می تواند پردازش همزمان هزاران تراکنش در ثانیه را امکان پذیر کند. بدیهی است که شیطان در جزئیات است ، اما به نظر می رسد که Conflux چندین تکنیک مشهور علوم رایانه را برای رسیدن به این موفقیت بزرگ ترکیب کرده است.
ورود به Conflux
متفاوت از برخی دیگر تلاش های مقیاس پذیری بلاک چین ، Conflux یک مدل اجماع جدید را به عنوان مکانیزمی برای گسترش اجماع تثبیت شده ناکاموتو پیشنهاد نمی کند. شبکه های قدرتمند مانند بیت کوین ، اجماع ناکاموتو به دلیل قدرتمند و ایمن فوق العاده و همچنین کند آزاردهنده شهرت پیدا کرده است. یک پروتکل اجماعی ناکاموتو معمولاً معاملات را در یک لیست مرتب از بلوک ها سازماندهی می کند که هر کدام شامل چندین تراکنش و پیوندی به نسخه قبلی خود هستند. هر بلوک تازه ایجاد شده در انتهای طولانی ترین زنجیره ضمیمه می شود تا زنجیره حتی طولانی تر و در نتیجه برگشت مجدد سخت تر شود. در حالی که فوق العاده ایمن است ، مدل اجماعی ناکاموتو این محدودیت را دارد که تنها یک شرکت کننده می تواند در مسابقه برنده شود و در بلاک چین مشارکت کند.

برای رفع محدودیت های اجماع ناکاموتو ، چندین بلاکچین از گزینه های دیگری مانند تحمل خطای بیزانسی (BFT) که برای تعیین ترتیب به مدل سلسله مراتبی متکی است ، استفاده کرده اند. از معاملات با این حال ، یک مکتب فکری وجود دارد ، که مشخصاً شامل محققان پشت Conflux است ، که معتقد است بلاک چین های BFT نمی توانند به طور کافی در مقیاس غیرمتمرکز باشند (این بحث روز دیگری است). پروتکل های Conflux از رویکرد متفاوتی پیروی می کند که از یک ایده ساده استفاده می کند: "اگر بتوانیم بلوک های همزمان و معاملات را به صورت خوش بینانه پردازش کنیم و سفارش نهایی آن را به بعد از زمان وقوع موکول کنیم؟" اگرچه این ایده در ابتدا ممکن است مضحک به نظر برسد ، اما اگر در نظر بگیریم که اکثر معاملات به ندرت با هم در تضاد هستند ، منطقی به نظر می رسدبه موقع در بلاک چین که منجر به این فرض می شود که بلوک های همزمان به طور پیش فرض با یکدیگر در تضاد نیستند و باعث ایجاد همزمانی خوش بینانه می شود. چند مرحله ساده:
1) پردازش خوش بینانه بلوک های همزمان
2) سازماندهی بلوک ها به صورت نمودارهای غیر چرخشی مستقیم (DAG)
3) ابتدا در مجموع توافق کنید ترتیب همه بلوک ها (فرض کنید معاملات با هم در تعارض نیستند)
4) سپس دستور تراکنش را از دستور بلوک مورد توافق (به طور تنبلی تعارضات معامله را حل کنید)
به منظور پیاده سازی این موارد مراحل ، پروتکل اجماع Conflux حفظ پروتکل اجماع دو نوع روابط بین بلوک ها را حفظ می کند. هنگامی که یک گره شرکت کننده یک بلوک جدید در Conflux ایجاد می کند ، گره یک بلوک والد (قبلی) را برای بلاک جدید شناسایی می کند و یک لبه والد بین این دو بلوک مانند بیت کوین ایجاد می کند. این لبه های اصلی Conflux را قادر می سازد تا به اجماع غیرقابل برگشت ثابت در دفتر کل خود دست یابد. نتیجه نهایی این است که لبه های بین بلوک ها یک نمودار غیر چرخه ای مستقیم (DAG) ایجاد می کنند که هم پیمایش آسان است و هم سطح خاصی از مقاومت در برابر چنگال ها را معرفی می کند. از این منظر ، Conflux را می توان به عنوان یک پروتکل اجماعی ناکاموتو مبتنی بر DAG در نظر گرفت.
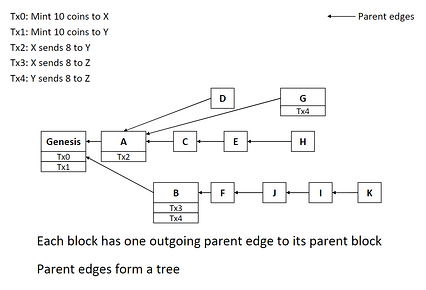
همه می دانیم که بلاک چین فراتر از یک پروتکل اجماع است. Conflux معماری نسبتاً ساده ای را ارائه می دهد که برخی از اصول اصلی بیت کوین را با ساختارهای مقیاس پذیری نوآورانه گسترش می دهد. معماری پایه Conflux شامل اجزای زیر است:
· Gossip Network: همه گره های شرکت کننده در Conflux از طریق یک شبکه gossip متصل می شوند که وظیفه پخش تراکنش به تمام گره های شبکه را بر عهده دارد.
· حوض تراکنش معلق: هر گره در شبکه Conflux دارای یک تراکنش معلق است که شامل تراکنش هایی است که توسط گره شنیده شده اما هنوز در هیچ بلوکی بسته بندی نشده اند. هرگاه یک گره یک معامله جدید از شبکه gossip دریافت می کند ، گره تراکنش را به مجموعه خود اضافه می کند.
· Block Generator: گره های Conflux از یک بلوک ژنراتور مبتنی بر Proof-Of-Work (PoW) برای ایجاد استفاده می کنند. بلوک ها برای معاملات در انتظار. //cdn-images-1.medium.com/max/426/1*ZxEAFLq6MNCMHFG1KQGYxQ.png">
اصول این معماری به Conflux اجازه می دهد تا امنیت و استحکام بیت کوین را با مقیاس پذیری مدرن ترکیب کند بلاک چین در یک شبکه واحد مدل Conflux سه ویژگی بسیار مطلوب شبکه های بلاک چین را تضمین می کند: امنیت ، پردازش همزمان تراکنش ها و صحت. با این حال ، تیم Conflux از تمرین نظری فراتر رفت و تصمیم گرفت ببیند که آیا برخی از ایده های آنها در عمل جواب می دهد.
Conflux in Action
تیم Conflux یک نمونه اولیه از پروتکل را اجرا می کند روی 800 نمونه AWS EC2 که هر کدام ده ها گره را اجرا می کنند. در مجموع آزمایشات از معماری حدود 10000 گره Conflux برای پردازش بلوک های 1MB-8MB در اندازه استفاده کرد. جای تعجب نیست که Conflux در مقایسه با سایر بلاکچین های ناکاموتو با اجماع مزیت روشنی را نشان داد.
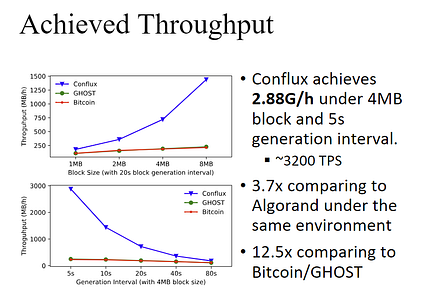
کمی چشمگیرتر این است که نسبت استفاده از بلاک Conflux بسیار بیشتر از سایر بلاک چین های قابل مقایسه عمل کند.
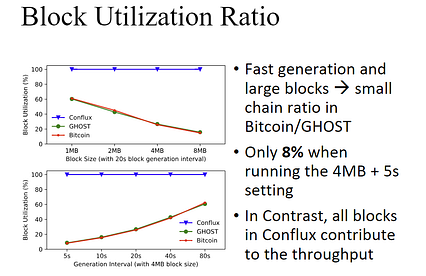
سایر آزمایشات نشان داد که Conflux می تواند به طور مداوم در حدود 20000 کاربر همزمان بدون تأثیر عمده در تأییدزمان.
Conflux رویکرد جدیدی را برای مقیاس پذیری بلاک چین با عدم خروج کامل از اصول بیت کوین اتخاذ می کند. در حال حاضر ، Conflux چیزی بیش از یک تمرین تحقیقاتی پیچیده نیست ، اما برخی از ایده های آن ممکن است به عنوان یک بلاکچین جدید تکامل یابد یا حتی در بیت کوین گنجانده شود.
چرا سولانا به توسعه دهندگان بلاک چین "رایانه جهانی" نیاز دارد
چرا سولانا به توسعه دهندگان بلاک چین "رایانه جهانی" نیاز دارد
کیل سامانی از Multicoin Capital تز سرمایه گذاری در سولانا ، اولین بلاک چین در مقیاس وب جهان را توضیح می دهد
این هفته ، سولانا از اتمام دور سرمایه گذاری سری A به مبلغ 20 میلیون دلار از مهمترین تخصیص دهندگان سرمایه در بلاک چین خبر داد. با افزایش سرمایه Multicoin ، این افزایش مشارکت قابل توجهی در پیگیری ایجاد اولین بلاک چین در مقیاس وب جهان از Distributed Global ، Blocktower Capital ، Foundation Capital ، Blockchange VC ، Slow Ventures ، NEO Global Capital ، Passport Capital و Rockaway Ventures دارد.
کایل سامانی ، بنیانگذار و شریک مدیریتی Multicoin Capital ، که دارای سبد سرمایه گذاری است که شامل بلاکچین نوآورانه می شود ، می گوید: "Solana نزدیکترین چیز به توسعه دهندگان بلاک چین" رایانه جهان "است که در روزهای اولیه رمزنگاری تصور می شد. مشاغل شامل Skale ، Bakkt ، Livepeer و Helium. "Solana یکی از قانع کننده ترین سیستم عامل های لایه 1 است که ما تا به امروز ارزیابی کرده ایم. ما بسیار مفتخریم که این دور را رهبری می کنیم و توسعه دهندگان را در همه جا تشویق می کنیم تا نگاهی جدی به سولانا بیندازند. این تز سرمایه گذاری Multicoin را برای پروژه سولانا توضیح می دهد. این مقاله فرصتی عالی برای آشنایی بیشتر با زیرساخت های فناوری Solana ، و معنای آن در رابطه با وضعیت توسعه بلاک چین فراهم می کند. ما برخی از عناصر کلیدی مقاله را در زیر با یک نسخه کوتاه از متن برجسته می کنیم ، اما کل مقاله نیاز به خواندن دارد.

برای شروع ، شش ویژگی اصلی وجود دارد که همه توسعه دهندگان برنامه های دارای اعتماد به حداقل نیاز به موفقیت دارند و سولانا همه آنها را حفظ می کند:
توسعه دهندگان قراردادهای هوشمند نمی خواهند با لایه 2 و خرد کردن برخورد کنند. تمام هدف داشتن یک زنجیره قرارداد هوشمند این است که خود زنجیره همه پیچیدگی ها و سیستم اقتصادی سطح پایین را که برای محاسبه حداقل اعتماد مورد نیاز است ، خلاصه می کند و به توسعه دهندگان برنامه اجازه می دهد تا بر منطق برنامه تمرکز کنند. در واقع ، هنگامی که ویتالیک در ژانویه 2014 اتریوم را در میامی به جهان معرفی کرد ، دقیقاً همان چیزی است که وی بر آن تأکید کرد: هدف رایانه جهان این است که همه چیز را که مختص برنامه نیست ، انتزاع کند!
در حالی که بسیاری از آنها وجود دارد. انواع راه حل های مقیاس بندی که روی آنها کار می شود ، هر یک از آنها پیچیدگی های خاصی را برای توسعه دهندگان برنامه ، کاربران و به طور کلی اکوسیستم ایجاد می کند. آخرین شکل این پیچیدگی - آنچه من آن را "ایجاد چمدان اکوسیستم" می نامم - به ویژه مقابله با آن چالش برانگیز است. همه راه حل های مقیاس ناهمگن پاسخ به این واقعیت است که ، تا به حال ، هیچ کس نمی داند که چگونه لایه 1 را مقیاس بندی کند و در عین حال تا زمان سولانا تمرکززدایی معماری و سیاسی کافی را حفظ کرده باشد.
مورد سولانا یکی است که توسعه دهندگان مجبور نیستند به راه حل های مقیاس بندی وابسته باشند (توسعه دهندگان مطمئناً لایه 2 را مستقر می کنندچیزهایی در بالای سولانا ، و آنها قادر خواهند بود زیرا سولانا بدون مجوز است). در بیشتر موارد استفاده ، توسعه دهندگان مبتنی بر Solana اصلاً مجبور نیستند به مقیاس بندی فکر کنند ، زیرا تمام لایه لایه 1 سولانا پیچیدگی انتزاعی است.
سخت افزار ، نرم افزار و فراوانی محاسباتی
تا کنون در فناوری بلاک چین ، کمبود عرضه پول و کمبود محاسبه به حداقل رساندن اعتماد قبلاً با هم ترکیب شده است. سولانا اینها را جدا می کند. رایانه جهانی باید محاسبات فراوانی را ارائه دهد ، اما از پول کمیاب استفاده می کند.
اصل راهنمای سولانا این است که نرم افزار نباید مانع سخت افزار شود. این سه پیامد عمده دارد:
اول ، شبکه Solana به طور کلی با سرعت یکسانی از اعتبارسنج واحد عمل می کند. این در واقع بصری است: اگر نرم افزار مانع سخت افزار نشود ، شبکه با سرعت یک دستگاه واحد کار می کند ، فرض کنید پهنای باند تنگنا نیست (در این مورد بیشتر در بخش توربین زیر).
دوم ، مقیاس های عملکرد شبکه را در کنار پهنای باند و تعداد هسته های GPU تجمیع کنید. پهنای باند هر 24 تا 36 ماه دو برابر می شود و اتصالات اینترنتی مدرن تا حد زیادی از اشباع محدودیت های فیزیکی فیبر فاصله دارند. و در حالی که عملکرد CPU تک رشته ای دیگر مطابق قانون مور بهبود نمی یابد ، پردازنده های گرافیکی همچنان تعداد هسته های خود را هر 18-24 ماه دو برابر می کنند بدون هیچ چشم اندازی
و سوم ، به دلیل این واقعیت که سولانا عملکرد کل شبکه به طور خطی با سخت افزار زیرین رشد می کند ، سولانا فراوانی را در جایی که در حال حاضر کمیابی وجود دارد ایجاد می کند: محاسبه با حداقل اعتماد.

مرور کلی فناوری
هفت پیشرفت فنی عمده وجود دارد که سولانا را ممکن می سازد. سرفصل های بخش به توضیحات مفصل از تیم سولانا پیوند دارد. به منظور بالا رفتن از پشته:
موضوع مشترک این نوآوری ها را می توان در موارد زیر خلاصه کرد: یک کلمه: بهینه سازی سولانا واضح ترین نمونه ای است که از اولین مهندسی مبتنی بر اصول در هر لایه از پشته دیده ام. تیم به طور سیستماتیک هر نقطه را در آنجا شناسایی کردکه سایر زنجیره ها کند می شوند (به عنوان مثال ، سربار اجماع ، محاسبه تک رشته ای ، و ورودی/خروجی دیسک) و راه حل های منحصر به فردی برای رفع هر مشکلی طراحی کرده اند.
Libra and Move
تیم Libra فیس بوک یک ماشین مجازی و زبان برنامه نویسی جدید به نام Move ایجاد کرد. اگرچه Libra در زمان راه اندازی شبکه اصلی خود در سال 2020 قابل برنامه ریزی نخواهد بود ، اما تیم Libra قبلاً منبع کد Move را باز کرده است. و معلوم می شود که Move و Solana’s Pipeline VM بیشتر شبیه به هم هستند.
سولانا بطور طبیعی از Move پشتیبانی می کند ، از جمله BPF و پردازش تراکنش های موازی. این بدان معناست که توسعه دهندگان می توانند برنامه های کاربردی برای زنجیره مجاز Libra را به زنجیره Solana بدون مجوز منتقل کرده و تمام عملکردی را که سولانا ارائه می دهد دریافت کنند.
این یک کاتالیزور باور نکردنی برای سولاناست زیرا سولانا از Libra سود می برد. توزیع در حالی که هنوز به روشی کاملاً بدون اجازه کار می کند. بر اساس راه اندازی شبکه اصلی سولانا در اکتبر 2019 ، احتمالاً سولانا اولین زنجیره ای است که از برنامه های مبتنی بر Move پشتیبانی می کند.

برنامه های کاربردی منحصر به فرد
سولانا آنقدر کارآمد است که کلاس های کاملاً جدیدی از برنامه های کاربردی را که قبلاً غیرممکن بود ، فعال می کند. یک اوراکل که روی Solana اجرا می شود می تواند هر 400 میلی ثانیه به روزرسانی قیمت را ارائه دهد. مبادله غیر متمرکز که می تواند 30 هزار به روزرسانی قیمت را در ثانیه انجام دهد و هر 400 میلی ثانیه قیمت آن را تسویه کند. تیم سولانا برای ملاقات با توسعه دهندگان سراسر جهان ، پاسخگویی به س questionsالات و نشان دادن سیستم در عمل ، یک تور جهانی را آغاز می کند. آنها در اجلاس Web3 در اوت در برلین ، هفته بلاک چین Wanxiang در شانگهای در ماه سپتامبر و Devcon5 در ژاپن در ماه اکتبر ، علاوه بر رویدادهای کوچکتر در سراسر جهان حضور خواهند داشت. اگر قصد دارید در یکی از این رویدادها حضور داشته باشید ، لطفاً با تیم سولانا تماس بگیرید و سلام کنید!



 src = "https://cdn-images-1.medium.com/max/426/1*rVQlnCbq5W4R-2m_WNljTw.png">
src = "https://cdn-images-1.medium.com/max/426/1*rVQlnCbq5W4R-2m_WNljTw.png">
OpenAI دو مدل ترانسفورماتور را منتشر می کند که به طور جادویی زبان و بینایی رایانه را پیوند می دهند
OpenAI دو مدل ترانسفورماتور را منتشر می کند که به طور جادویی زبان و بینایی رایانه را پیوند می دهند
CLIP و DALL · E از GPT-3 برای تسلط بر کارهای پیچیده بینایی رایانه الهام می گیرد.
 منبع: https://www.rev.com/blog/what-is-gpt-3-the-new- openai-language-model
منبع: https://www.rev.com/blog/what-is-gpt-3-the-new- openai-language-model